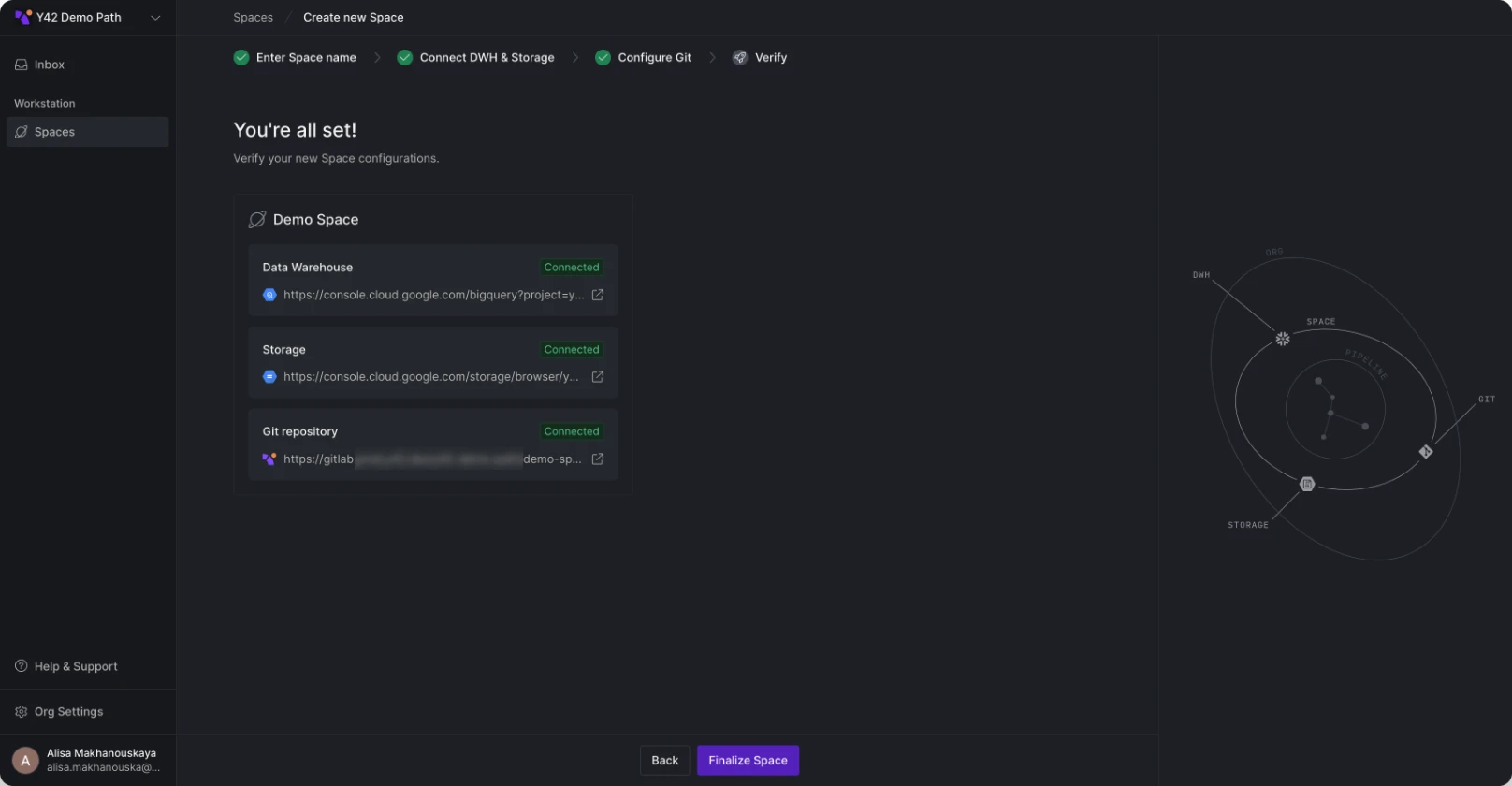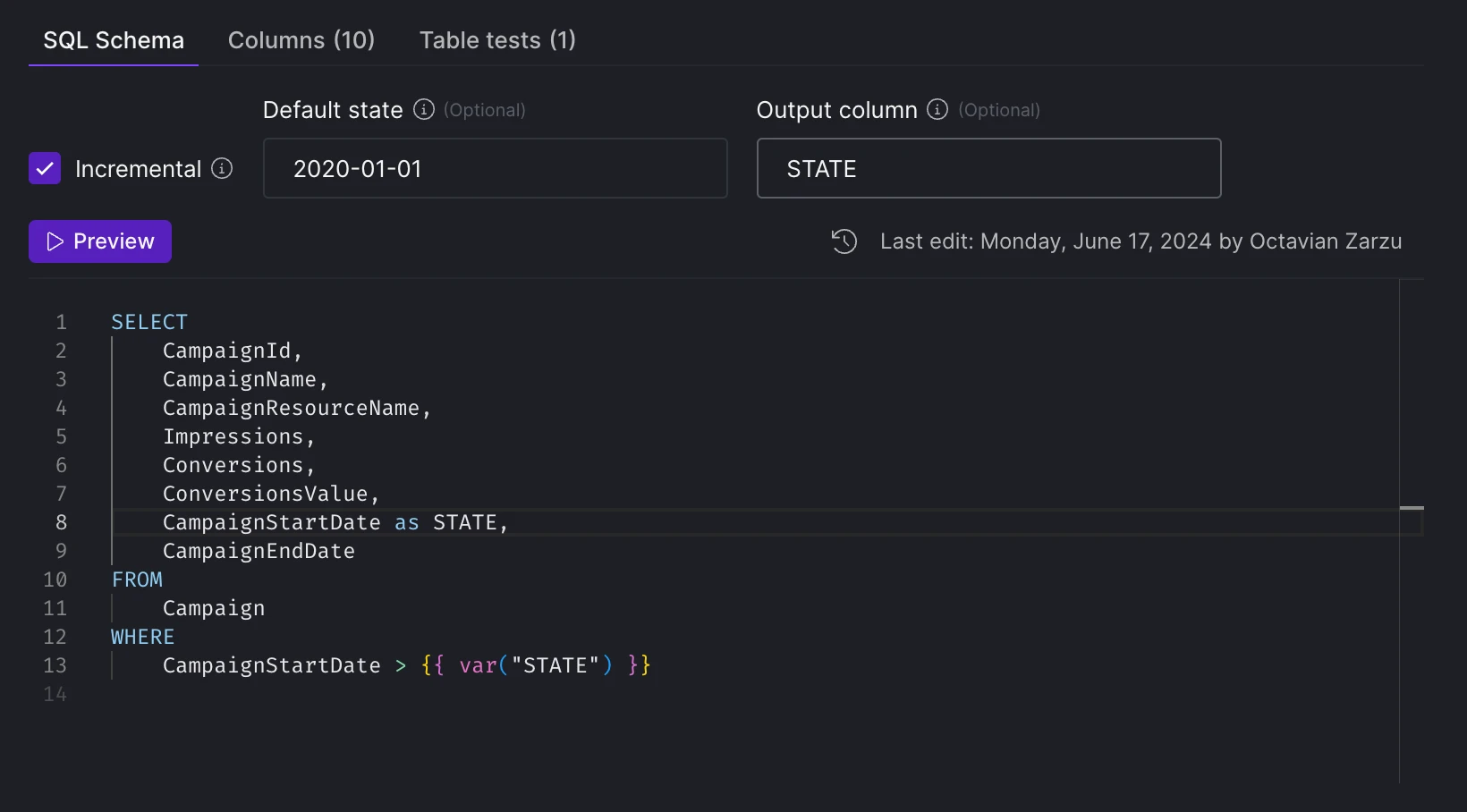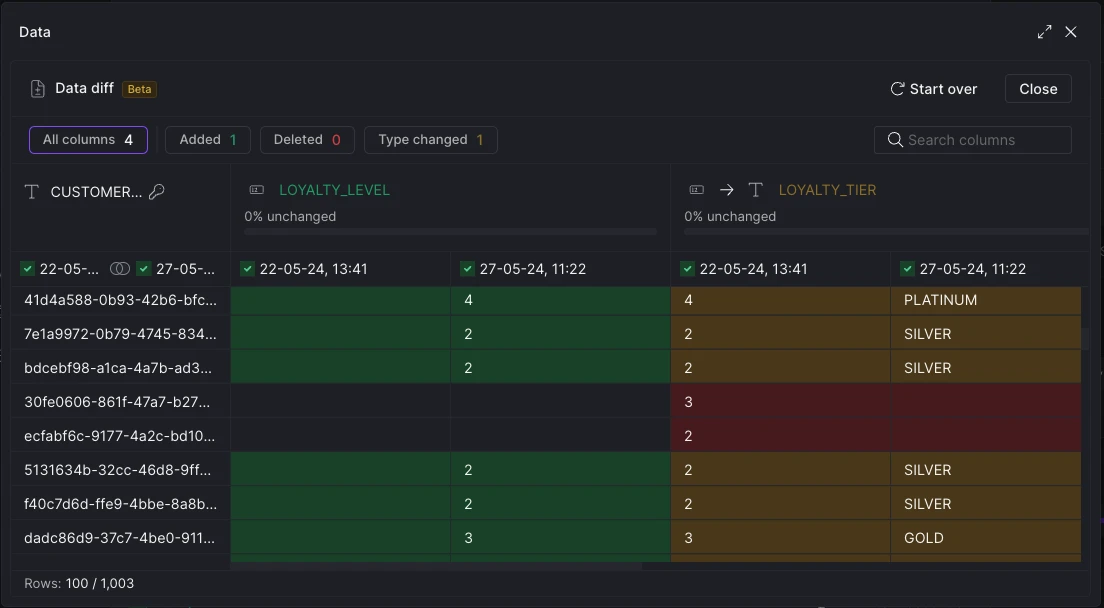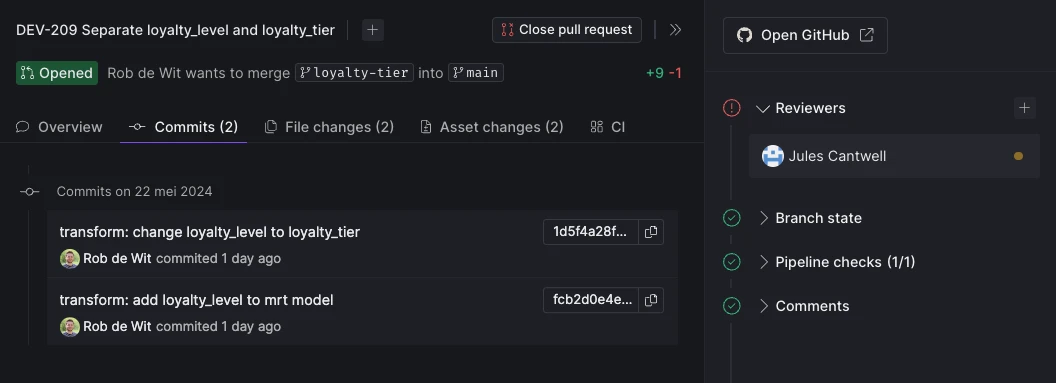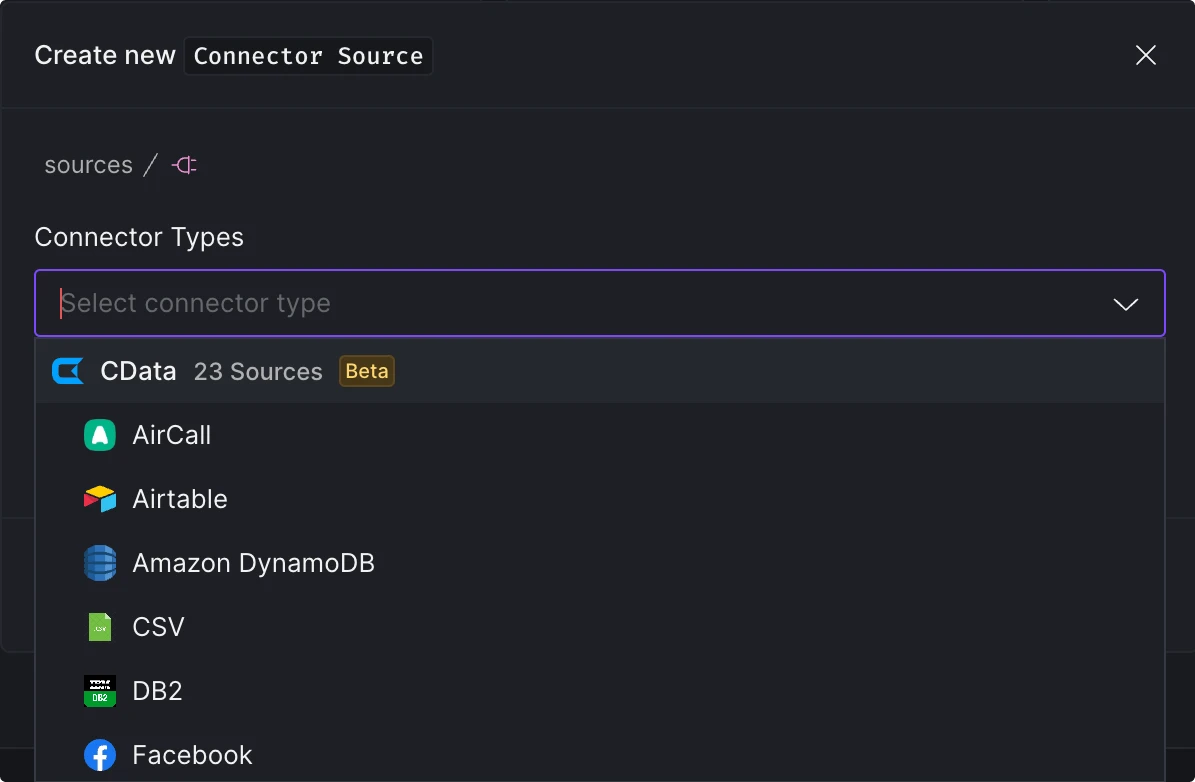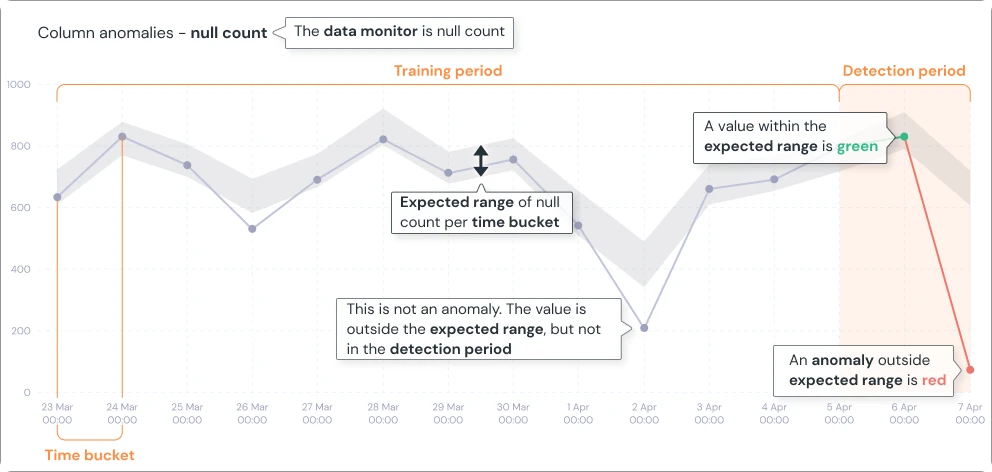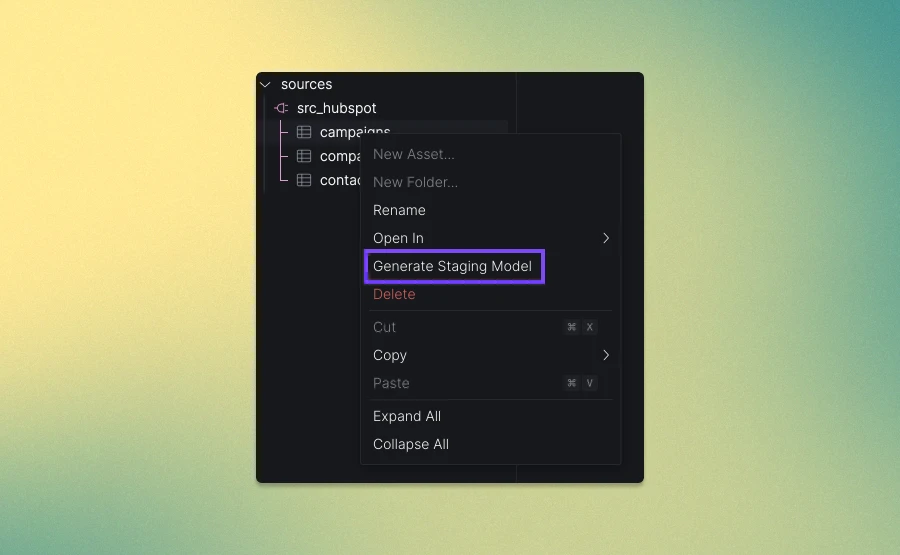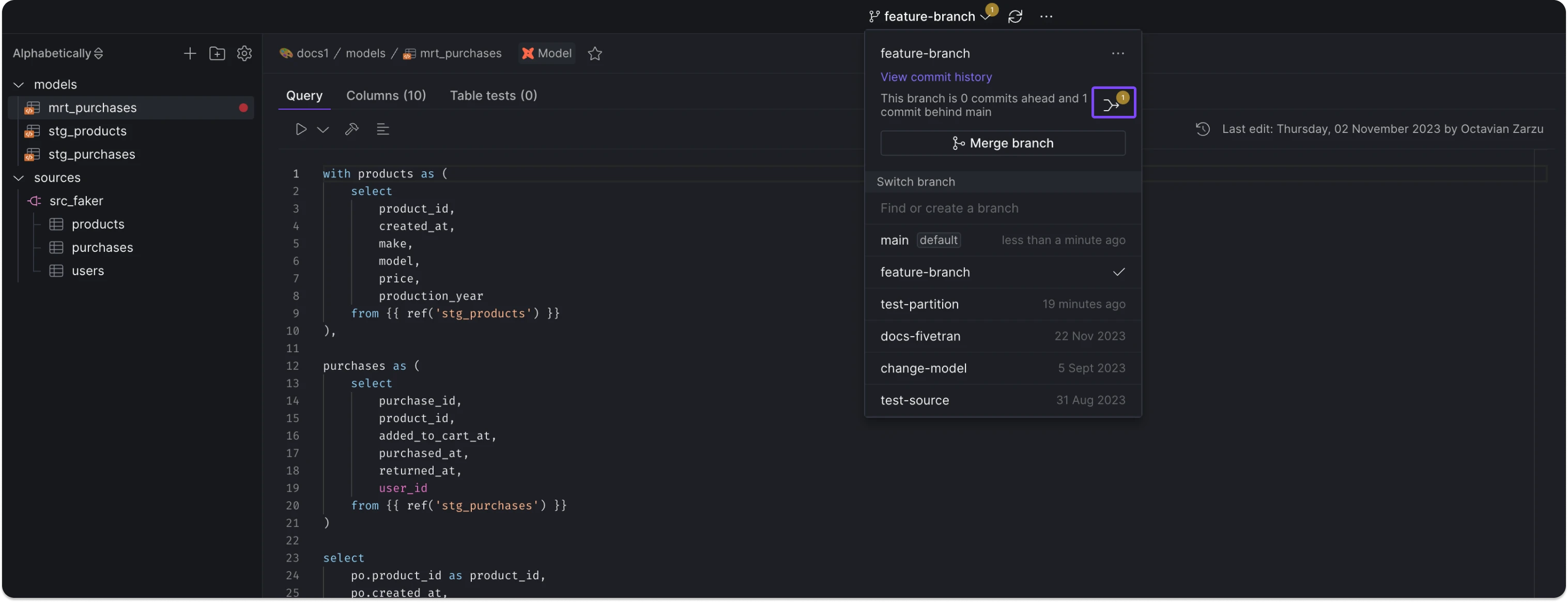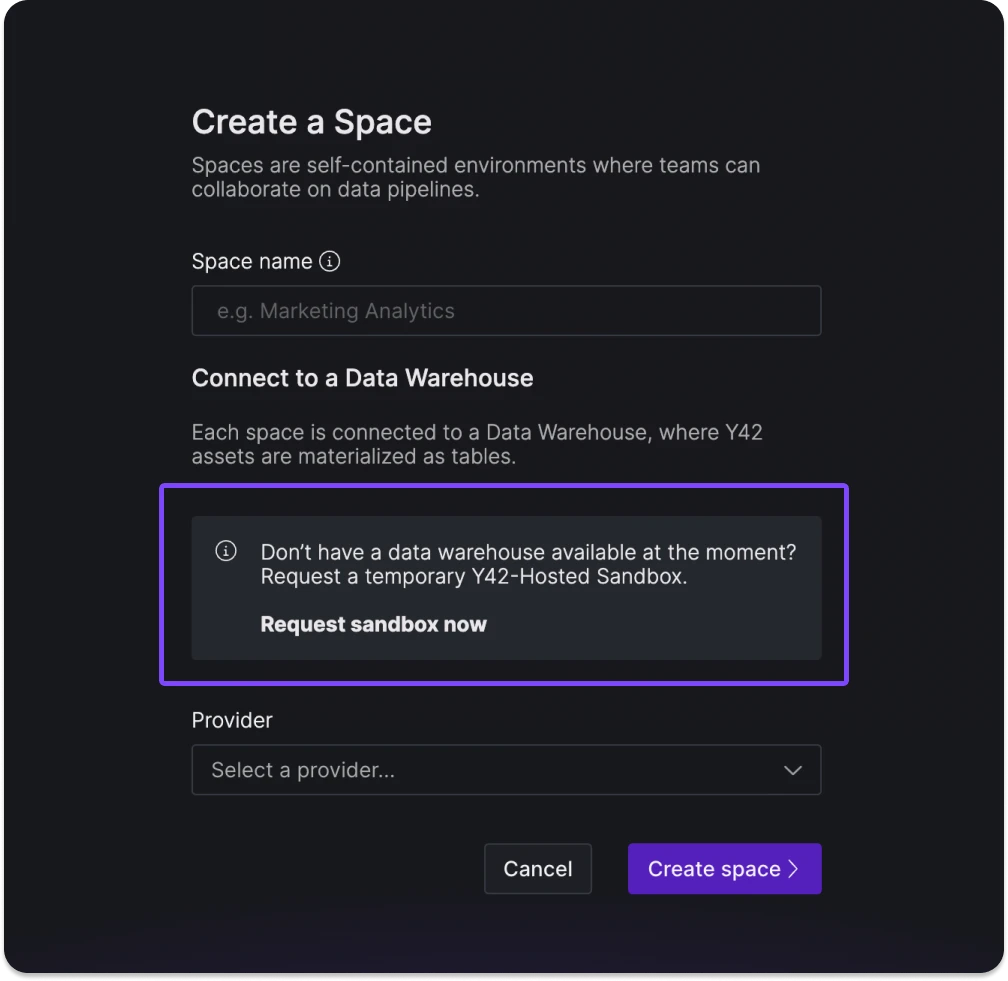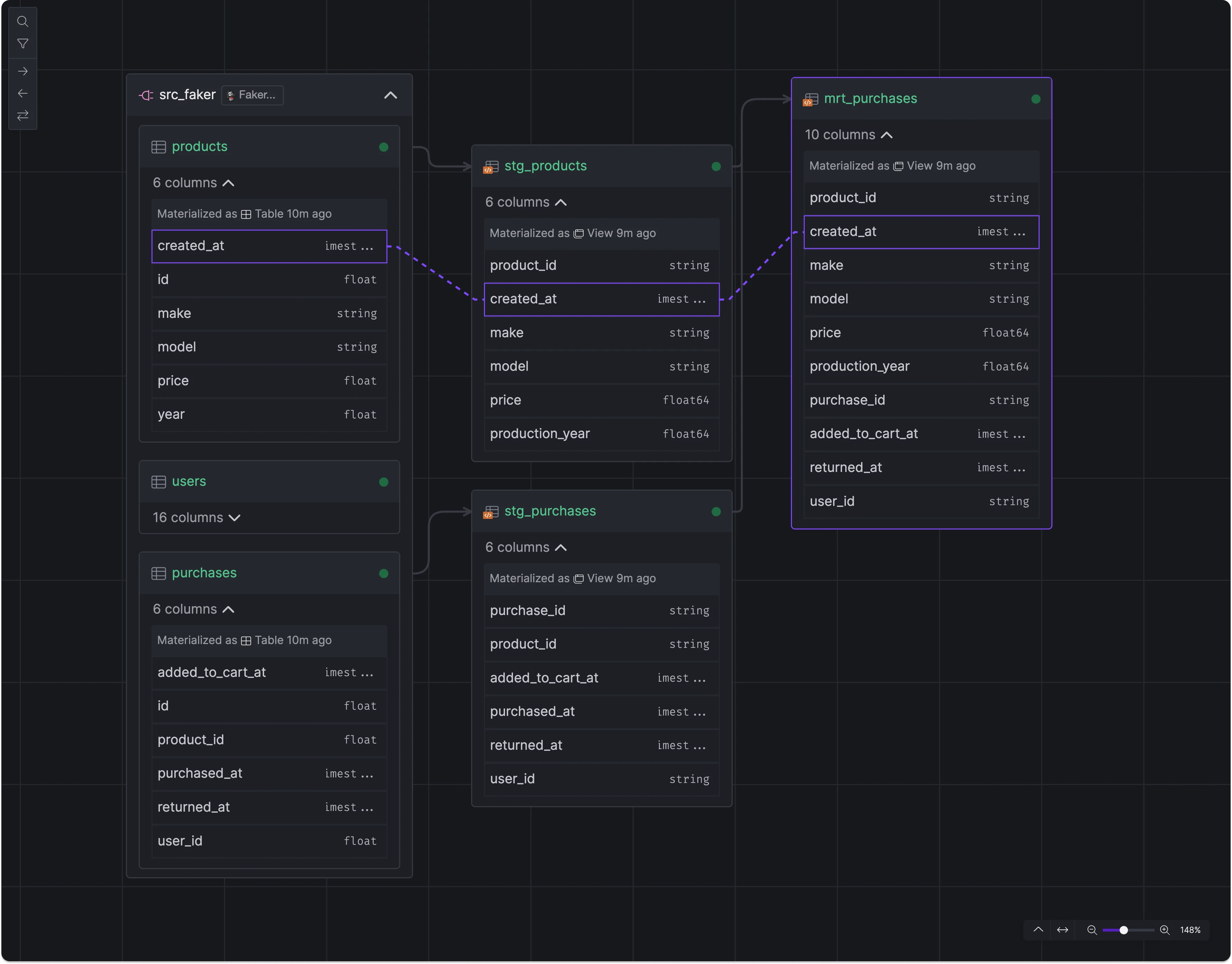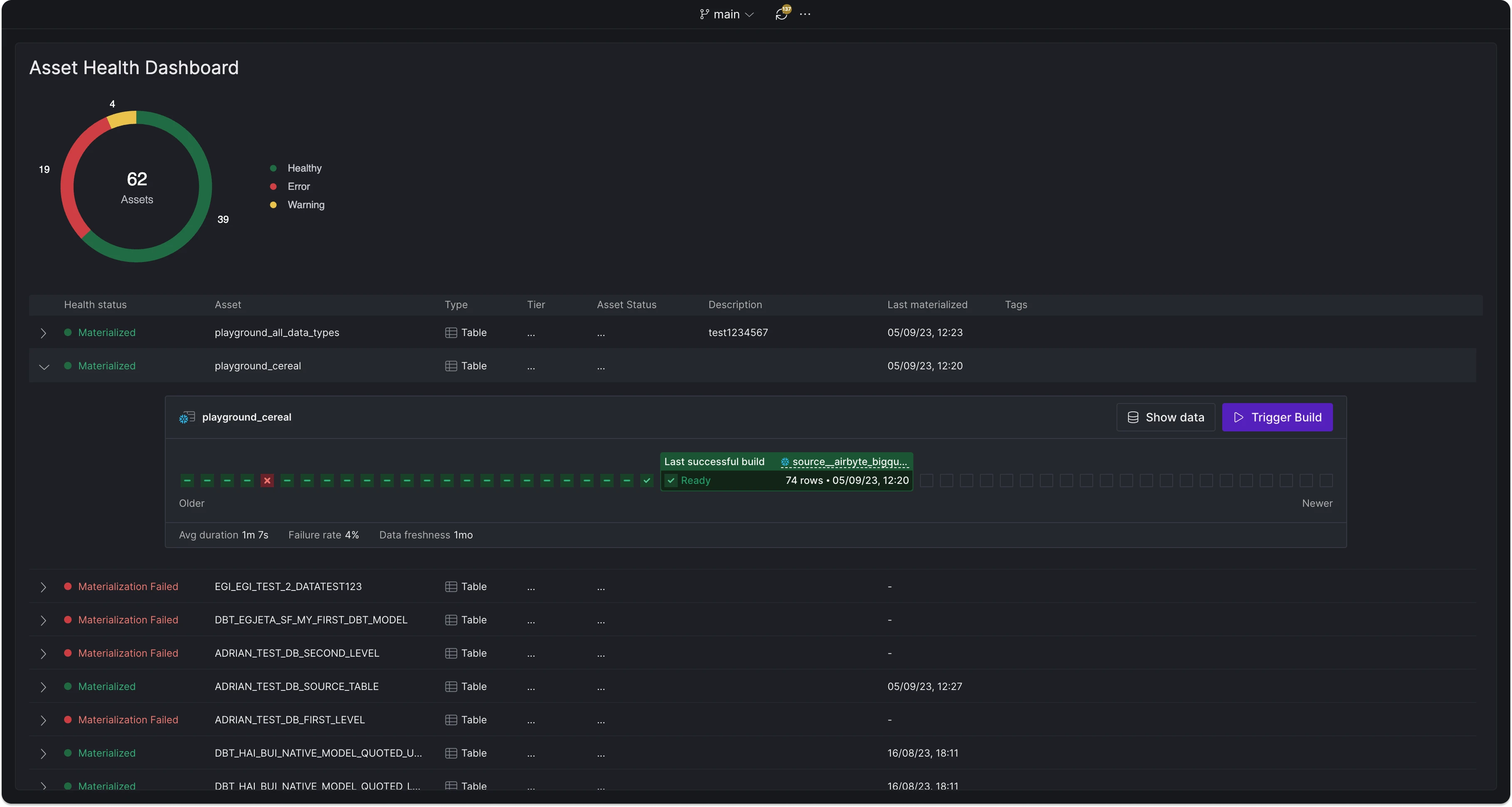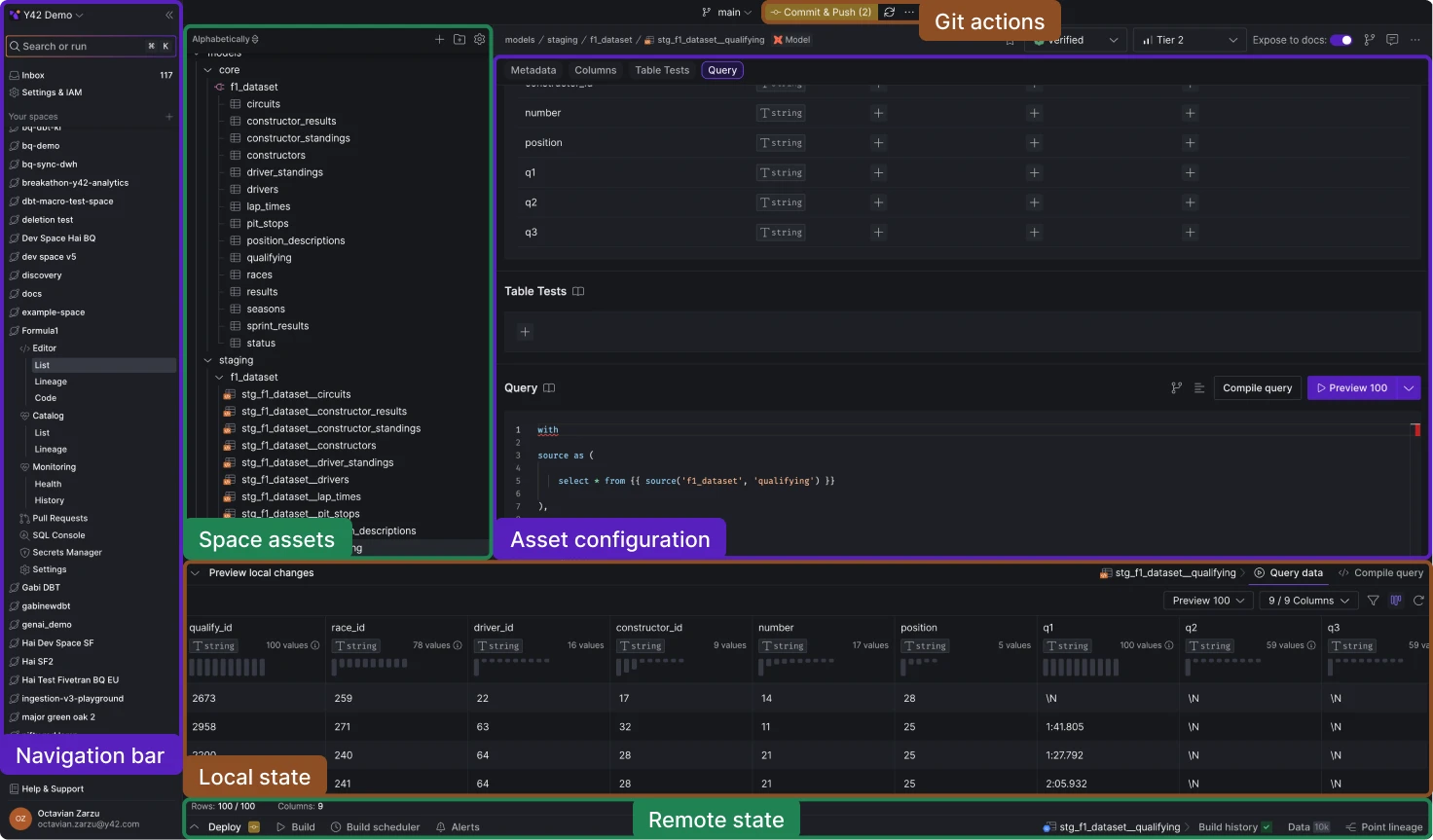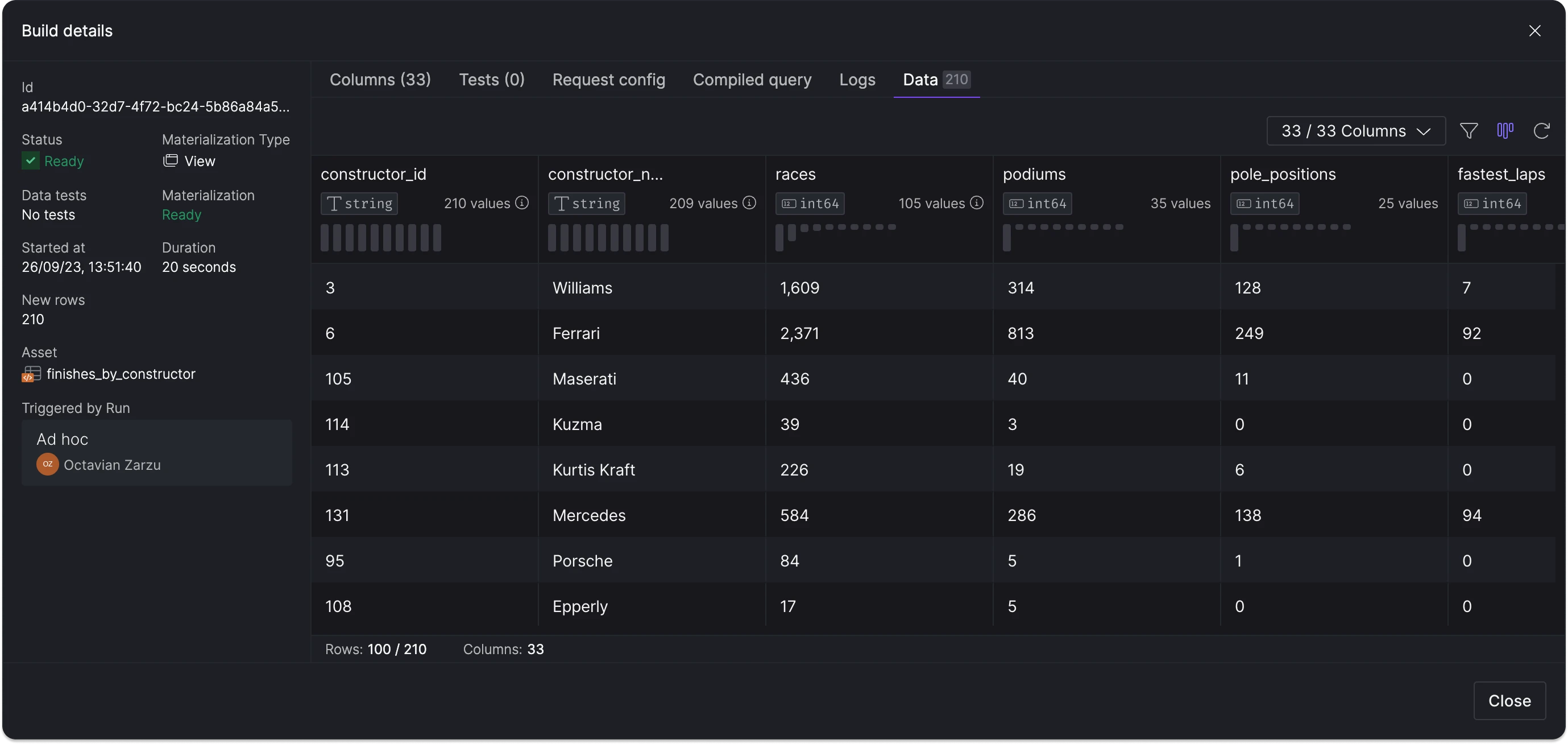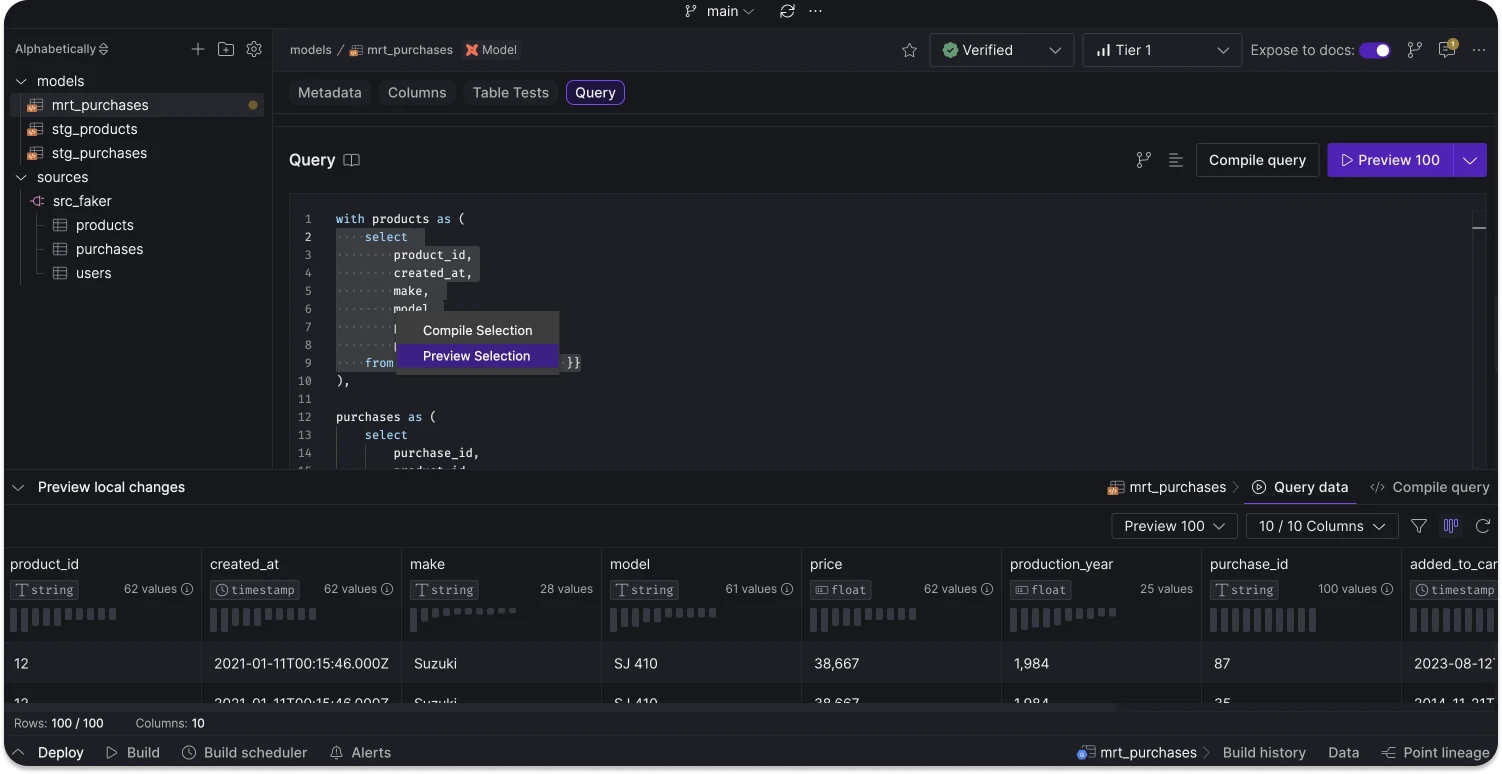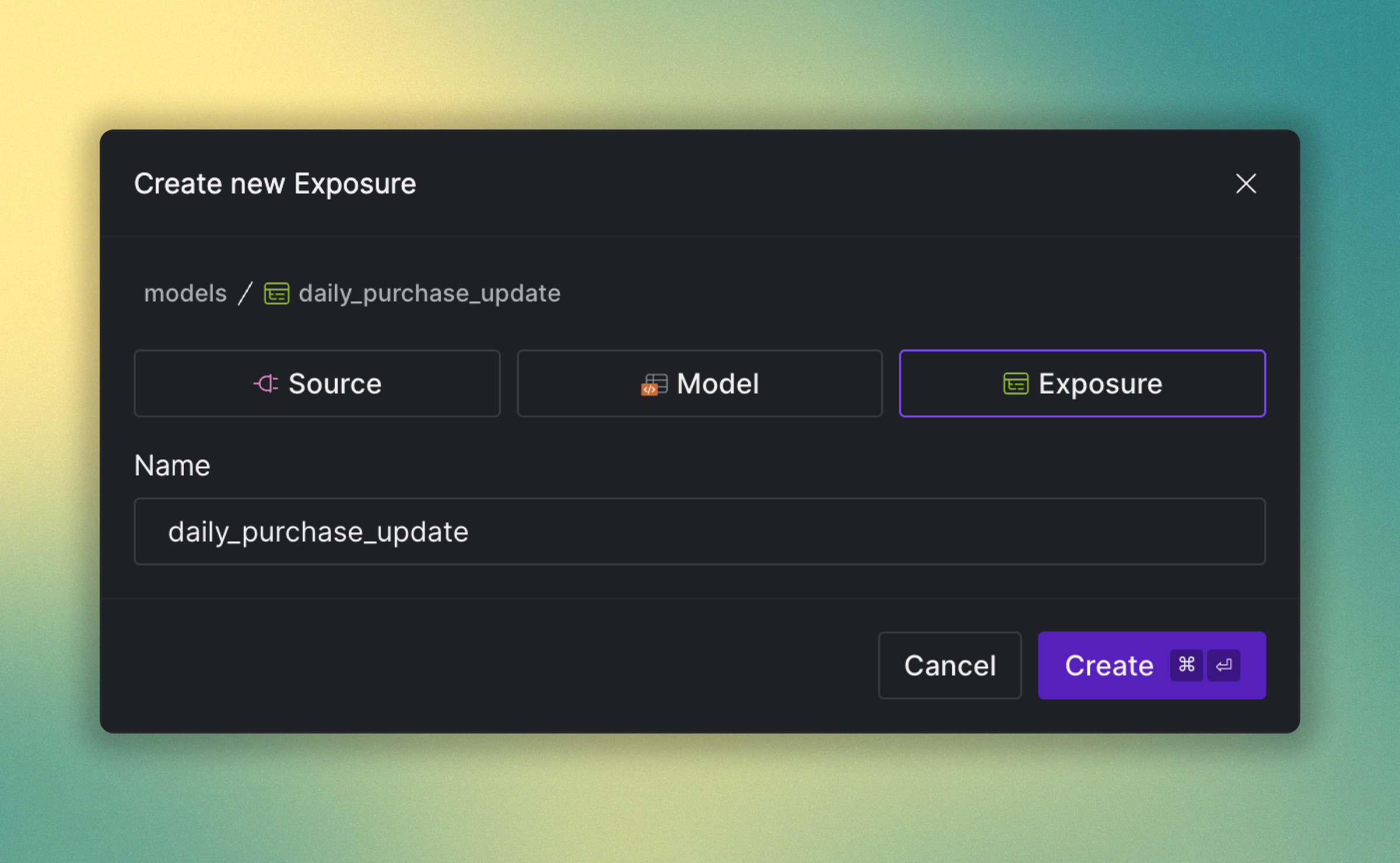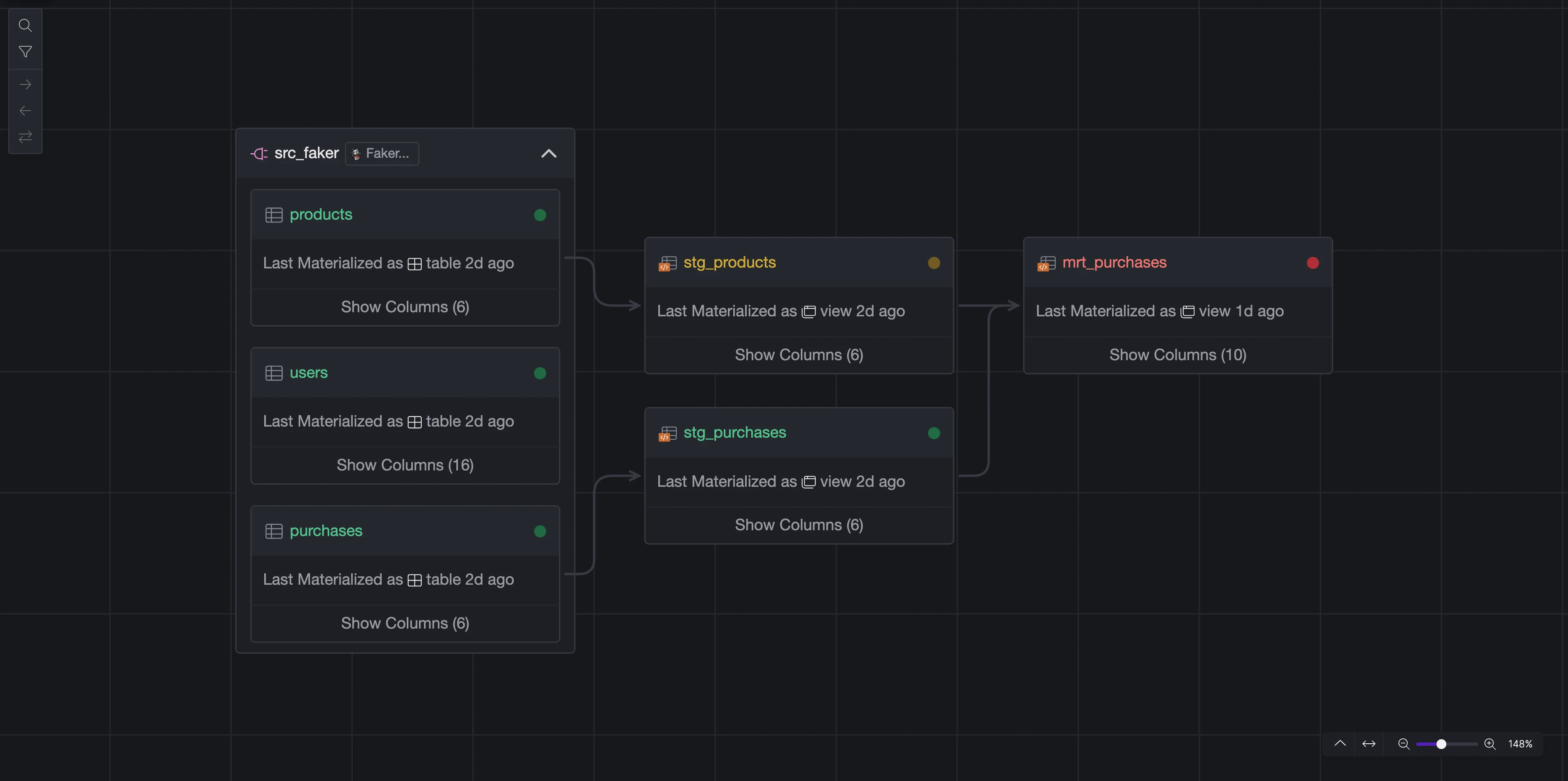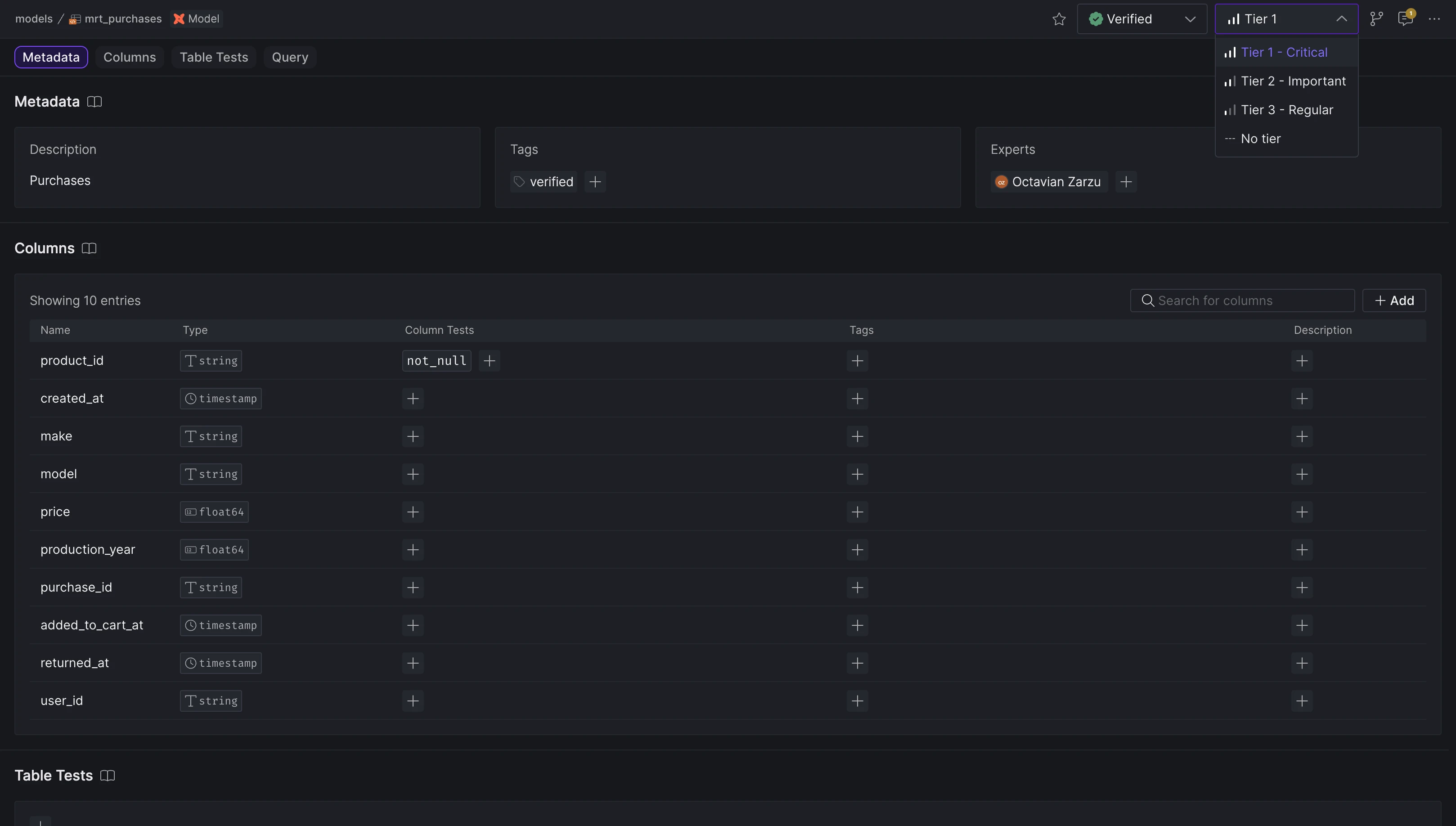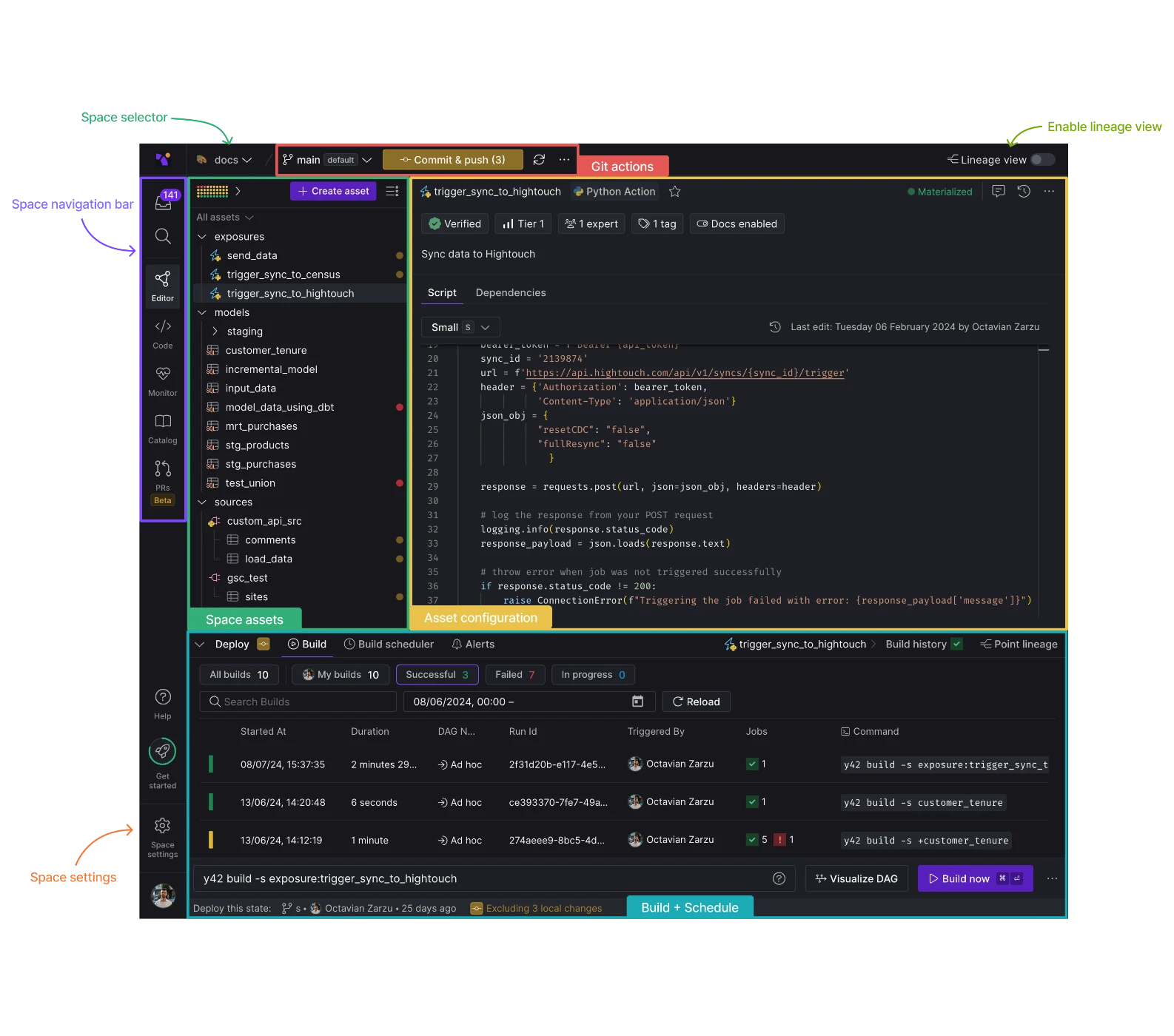
We've redesigned the platform interface to streamline navigation and better separate organizationa management. Key updates include:
- Two-Level Navigation: Navigation is now organized into two levels: organization and space, providing relevant context for different user activities.
- Space List Management: A new standalone page at the organization level allows for direct management of the space list.
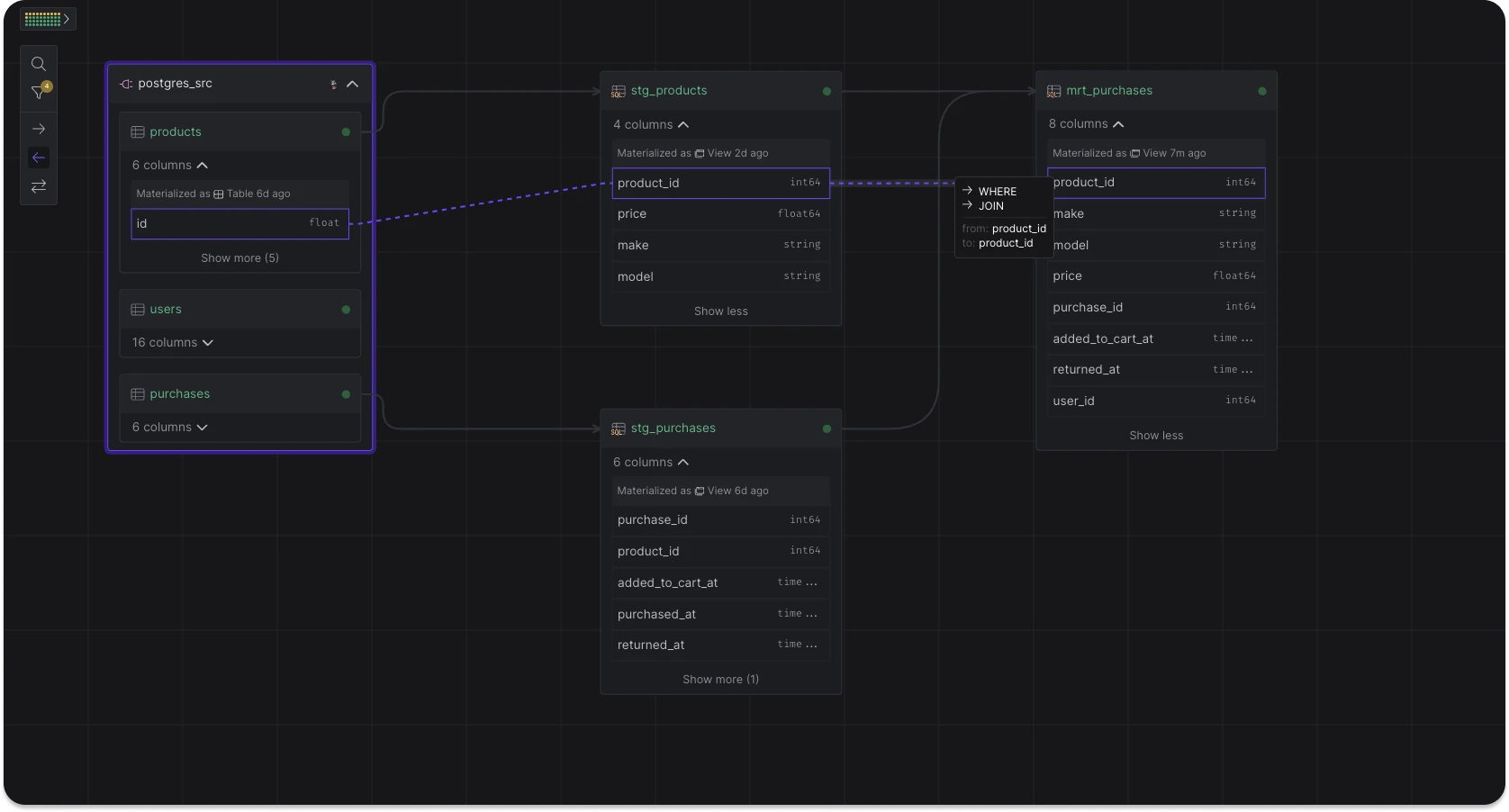
- Lineage View Mode: Lineage view can now be activated as a distinct mode from the space view's top right corner.
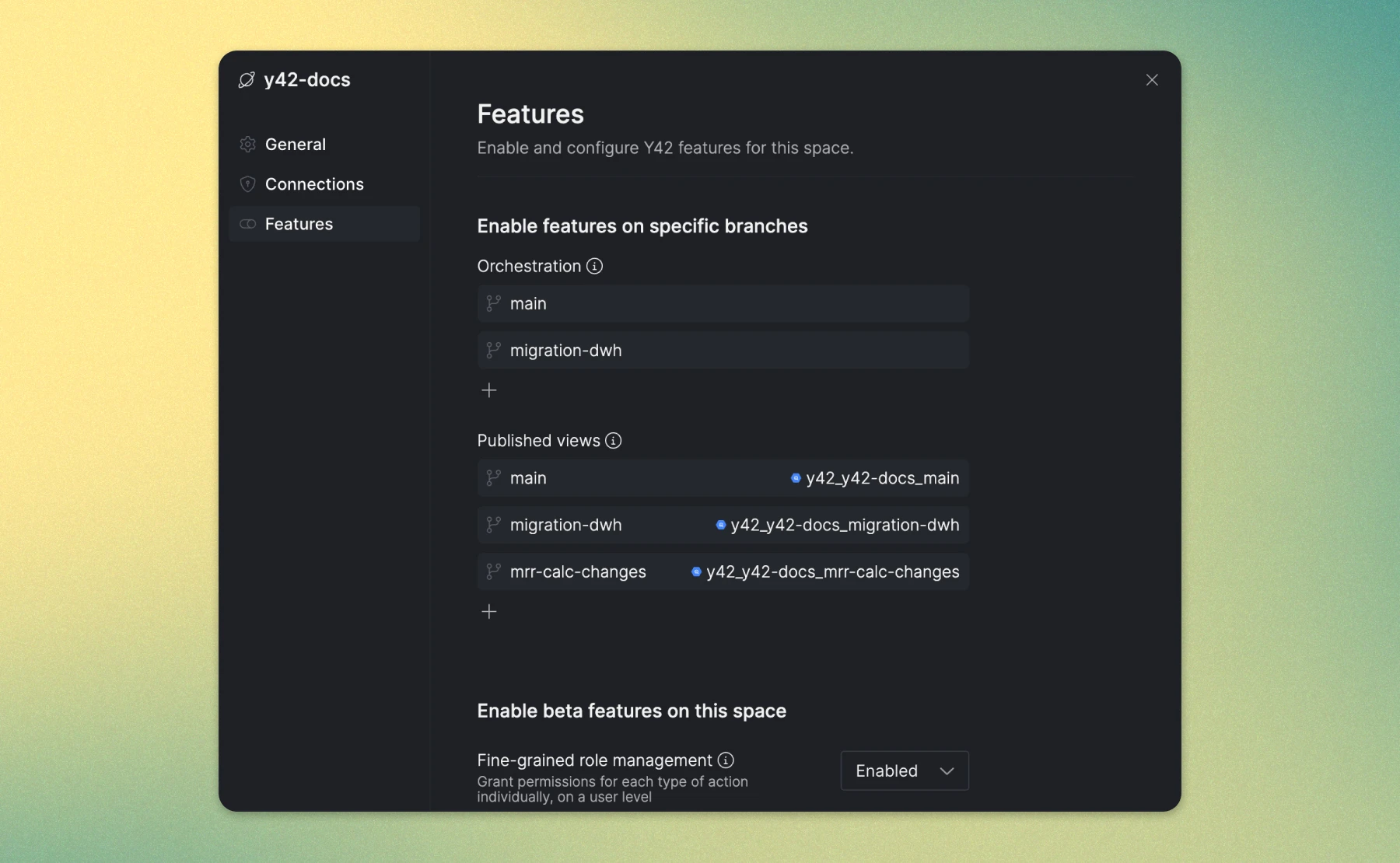
- Dedicated Settings Pages: Organization and Space settings are now accessed via separate pages for clearer configuration management.