manage changes with Git
Version control every byte of your data pipelines
From design to deployment, Y42 lets you manage all aspects of your data pipelines as code in a Git repository — so you have full control of your project.
Branch environments
Fully-fledged development sandboxes on demand
Spin up a self-contained development sandbox that never interferes with your production data pipelines. With branch environments, it’s never been easier to test changes in isolation — just create a branch and go.
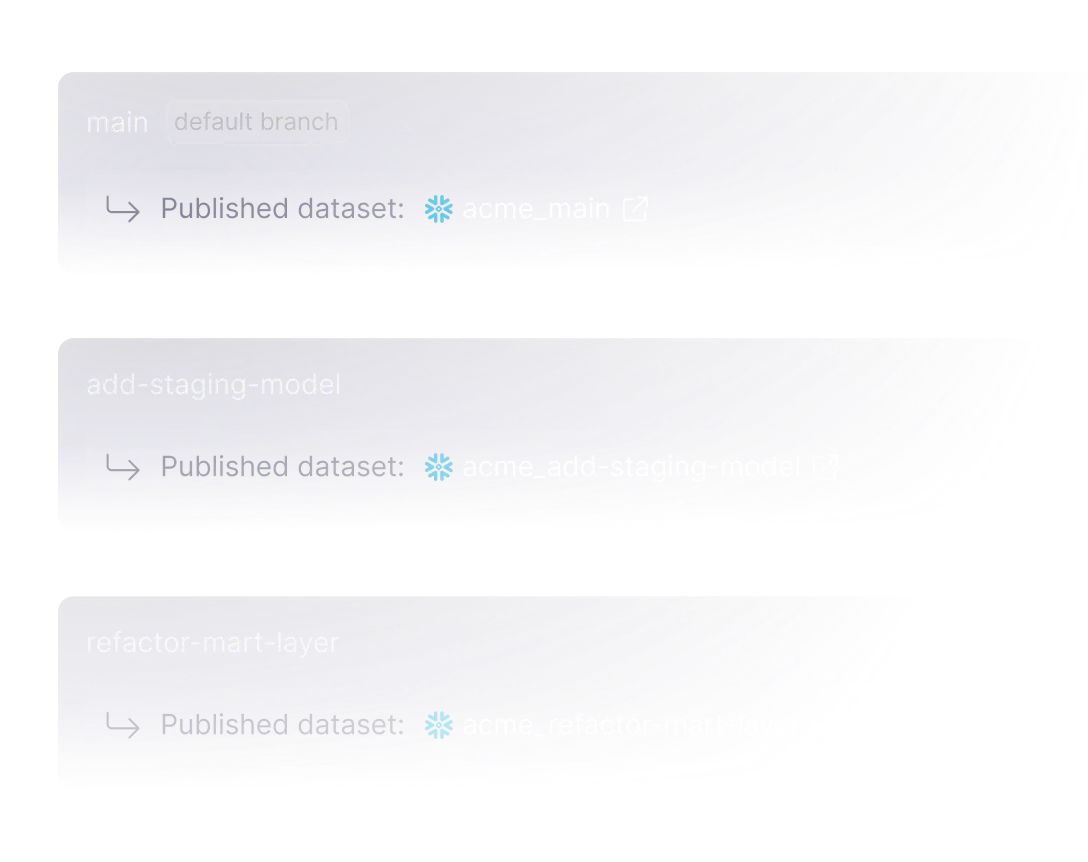
Branch environments
With one click, branch out from your main data pipelines and create an isolated environment that assigns each new table with a unique ID — so you’ll never have accidental overwrites.
Explore documentation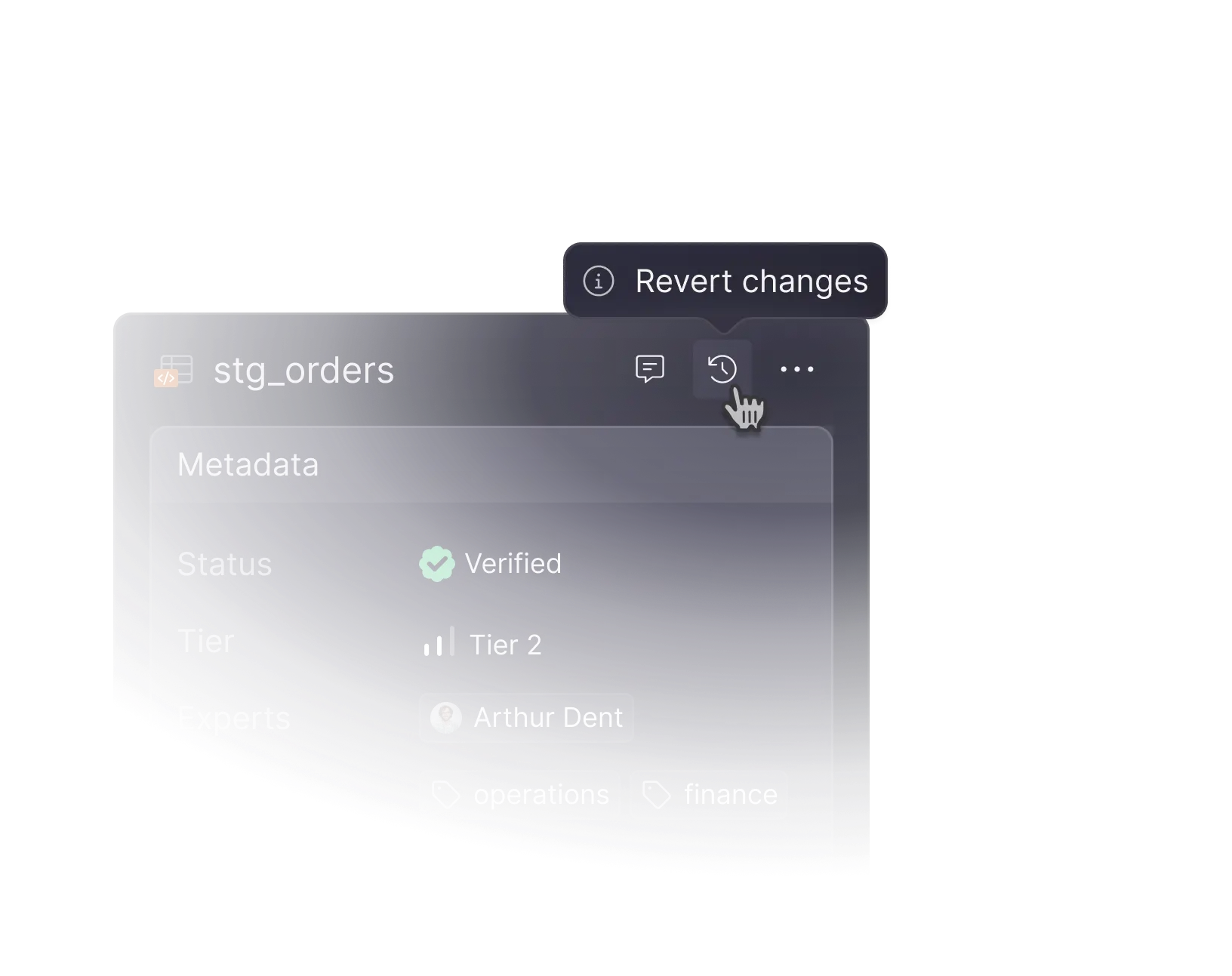
Instant rollbacks
Need to undo a change? Reverting the code automagically restores previous versions of your data. It’s instant — like having an “undo” button for you data pipelines.
Explore documentationMerge requests
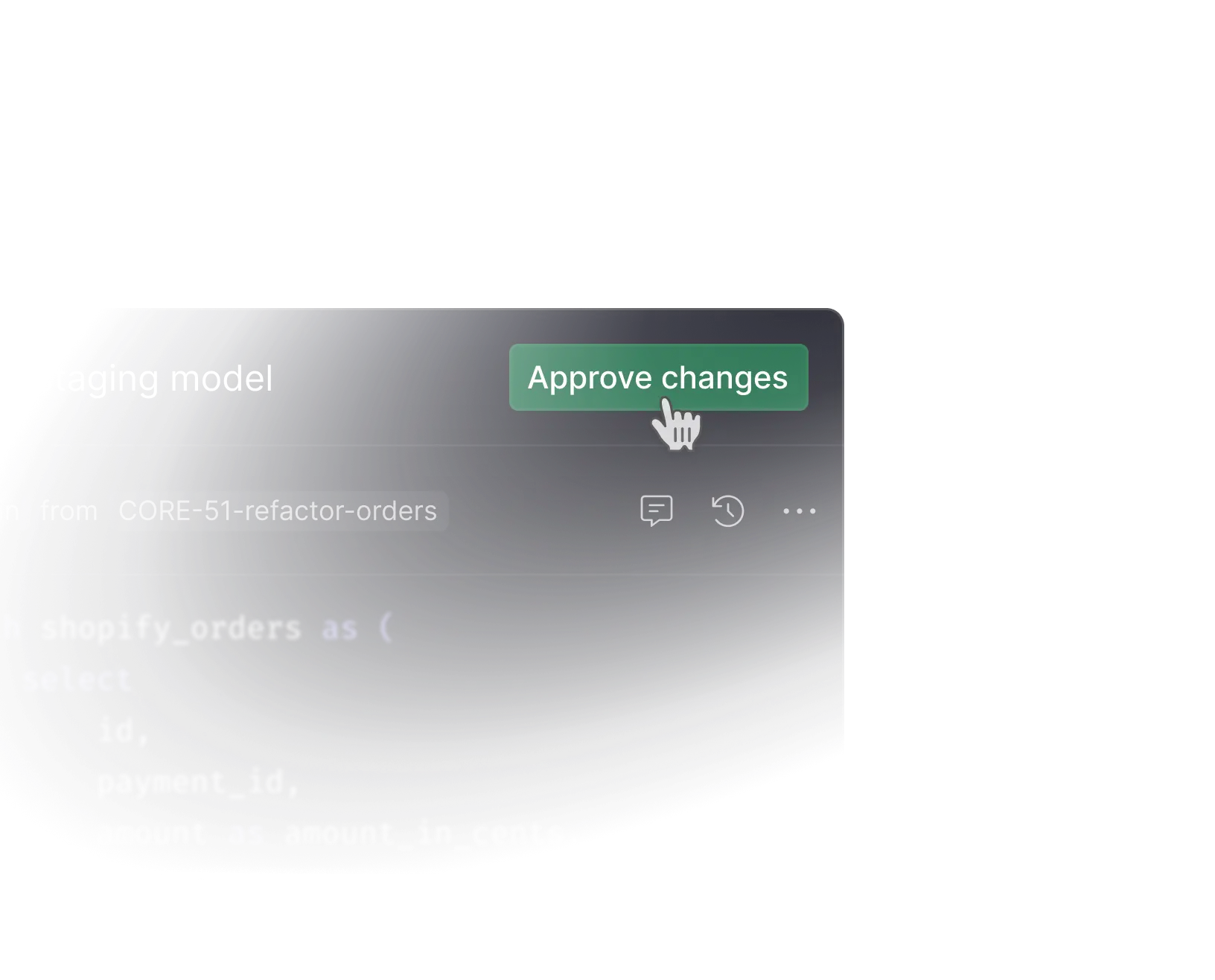
Review and approve changes before they go live
Ensure all changes made to your data pipelines are peer-reviewed before they are deployed to production. Through merge requests, every line of code bears your team's stamp of trust.
Explore documentation
Continuous integration
No untested changes shall pass into production
When a merge request is created, Y42’s continuous integration (CI) automatically checks your modified data pipelines. Even if the changes have been reviewed and approved, they must pass all tests before it can be deployed.

Automate testing
Configure automated testing in 2 minutes. For every new merge request, Y42 tests your data pipelines and shows you whether the proposed change introduces any errors.
Explore documentation
Pre-tested changes
Once your changes have been validated in an environment that mirrors production, they are automatically “pre-cleared” for approval — so you can skip unnecessary repeated testing.
Explore documentationContinuous deployment
No need to duplicate tables — just create and merge branches
Y42 versions both the code and data, so when you merge changes into production, the latest materialized data follows along with it... and you'll never have to run the same computations twice.
Automate deployments
Y42’s Virtual Data Build system detects pre-built tables from your existing environments and integrates them directly in production. Approved changes are deployed instantaneously.
Explore documentation
Run only what’s changed
Automatically identify and run only the parts of your data pipelines that are impacted by code changes — so you can reduce computational costs and deployment time.
Explore documentationReady to unlock your data universe?
The only Turnkey Data Orchestration Platform. Get started — for free.