Ingest data using CData
Use SQL to ingest data from your operational systems into your data warehouse.
Overview
Y42 offers managed ingestion powered by CData (opens in a new tab) to ingest your data. For each data ingestion job, Y42 creates an instance of the CData Python connector (opens in a new tab).
To ingest your data using CData, you need to create the following two resources in your Y42 space:
- Source: For each CData connector you will need to create a
sourceobject. Sources provide metadata information about external data sources, such as table or column-level information. - Connection: Connections hold information about authentication. When you set up a source, you don't need to worry about creating additional accounts, you can use your existing account with the data provider (e.g., username and password for database sources or an API token).
For a deeper dive into features of each connector, please refer to the individual documentation page for each source.
Ingest data using CData connectors
Create a CData connector asset
Click on the + Create Asset button in the asset navigation menu and select Connector from the options.
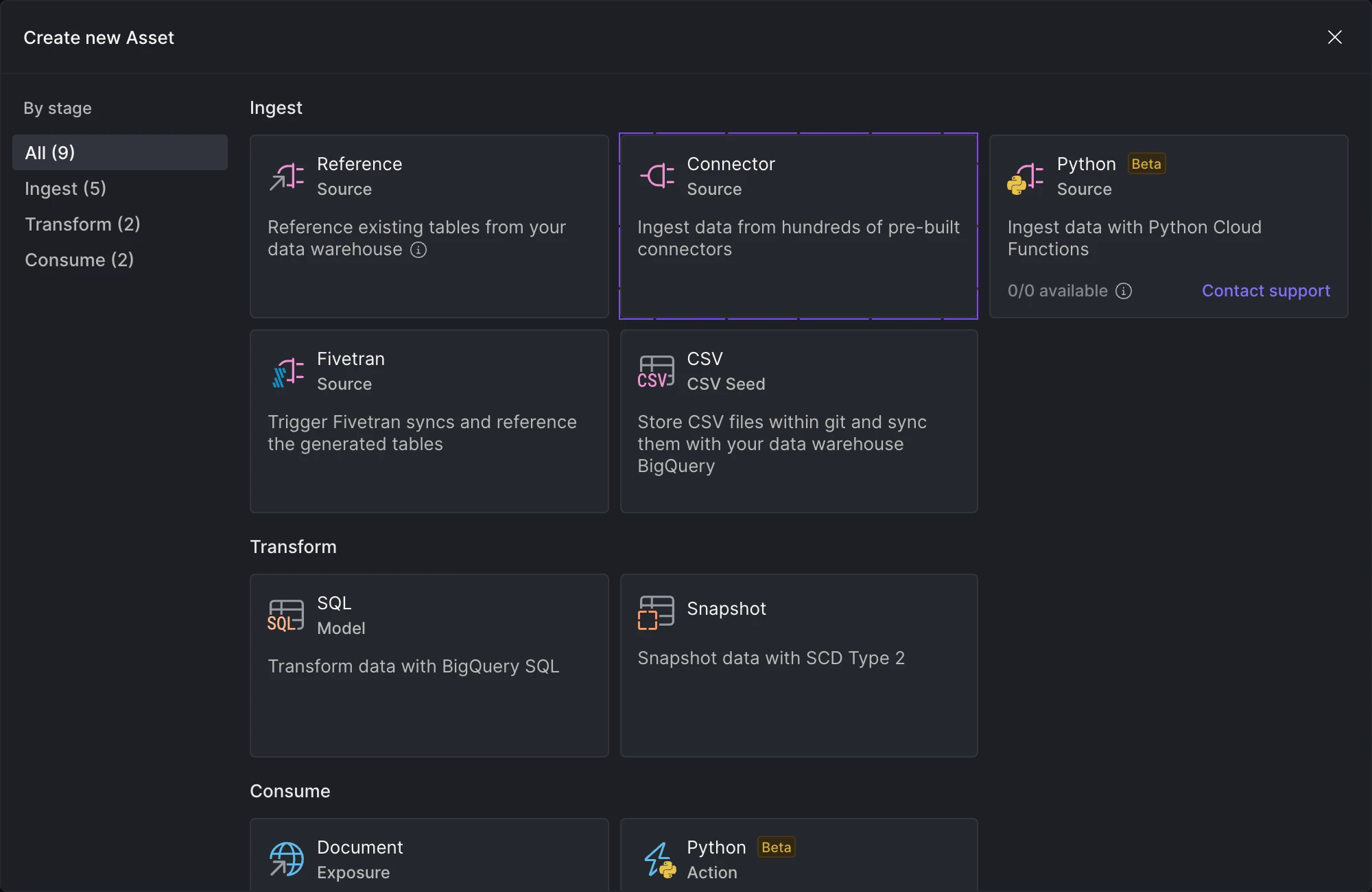
Create a new CData connector asset.
Choose the desired Connector Type for your new connector asset and provide a meaningful name for it.
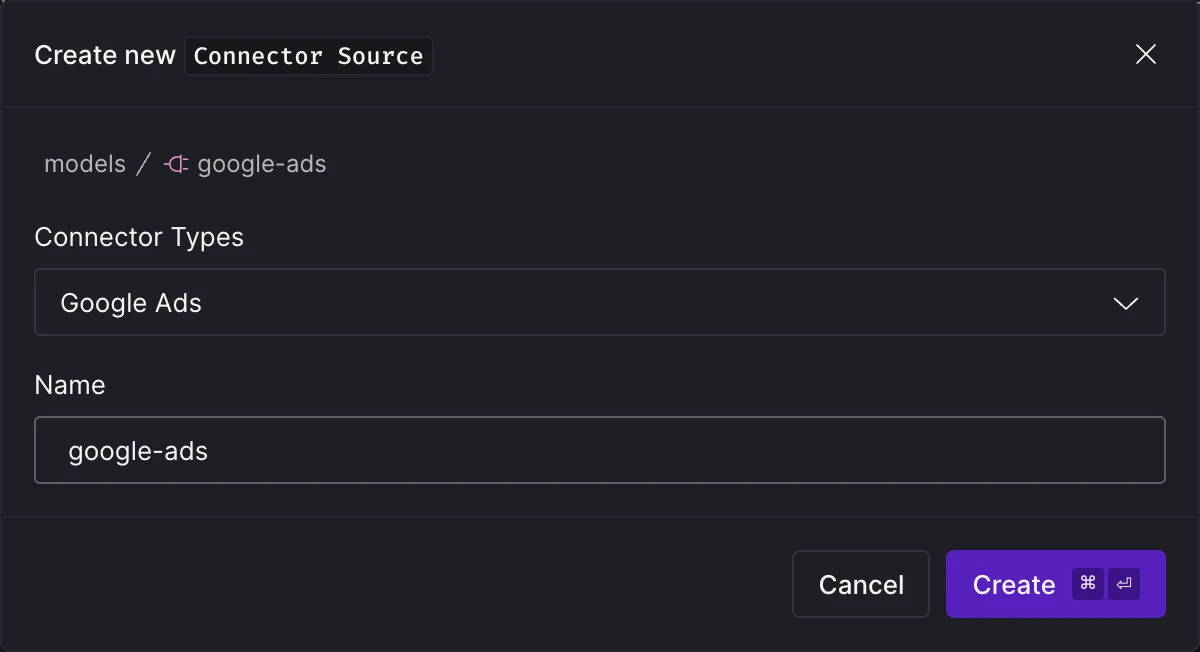
Choose the Connector Type.
Add new or use an existing connection
You can define a new connection or reuse an existing one. Learn more about connections here.
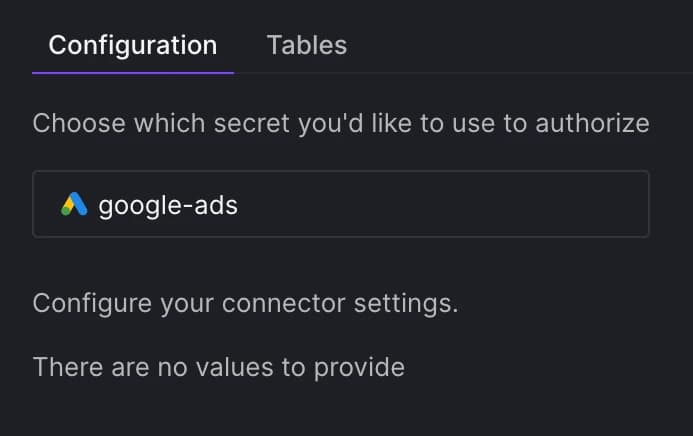
Add new or use an existing connection.
Add tables
Navigate to the Tables tab and select Add Table. Enter a name for the table you wish to add.
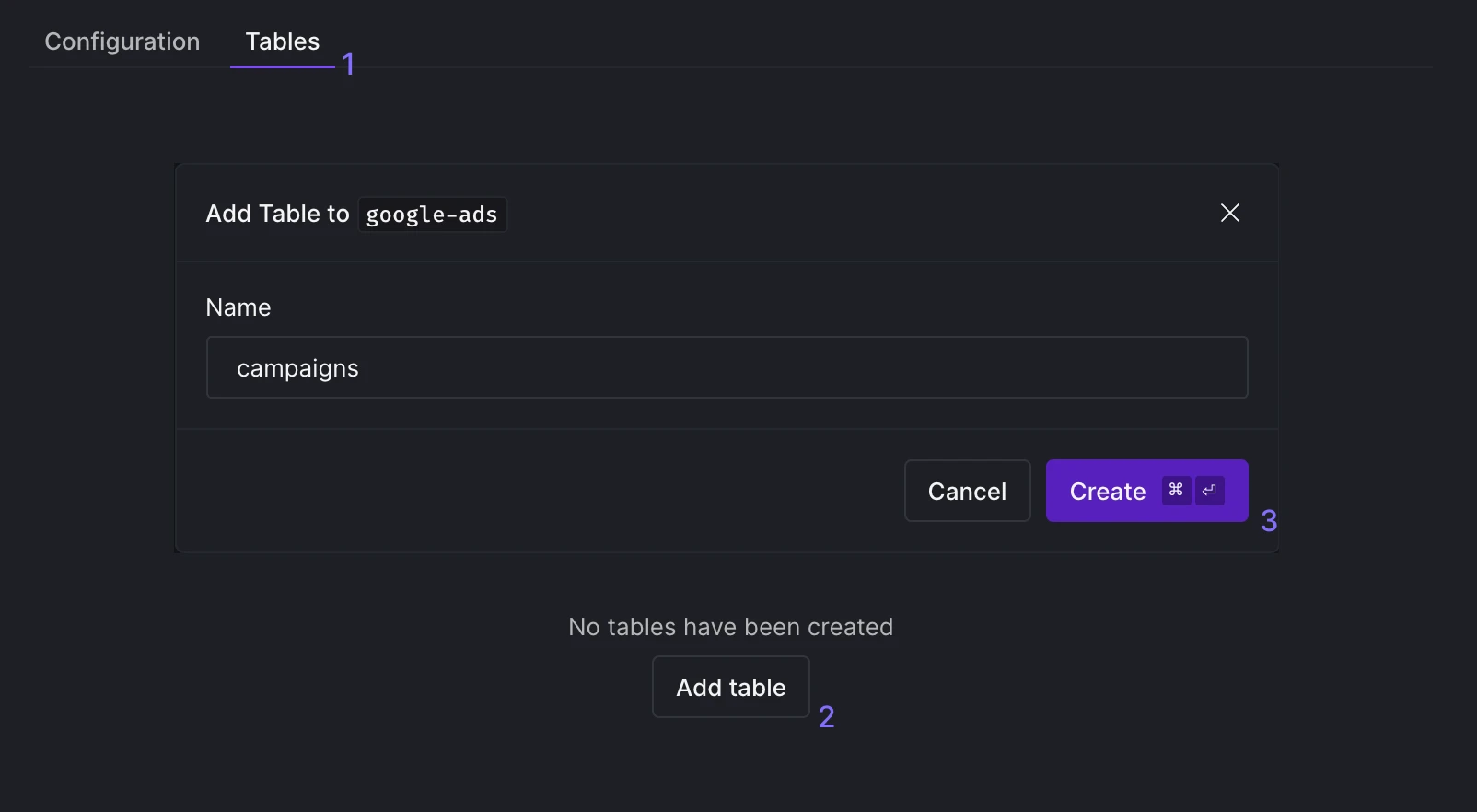
Add table(s) to your CData Connector.
Discover source table schema
You can discover the source table schema by either:
- Using the query
SELECT * FROM sys_tables;
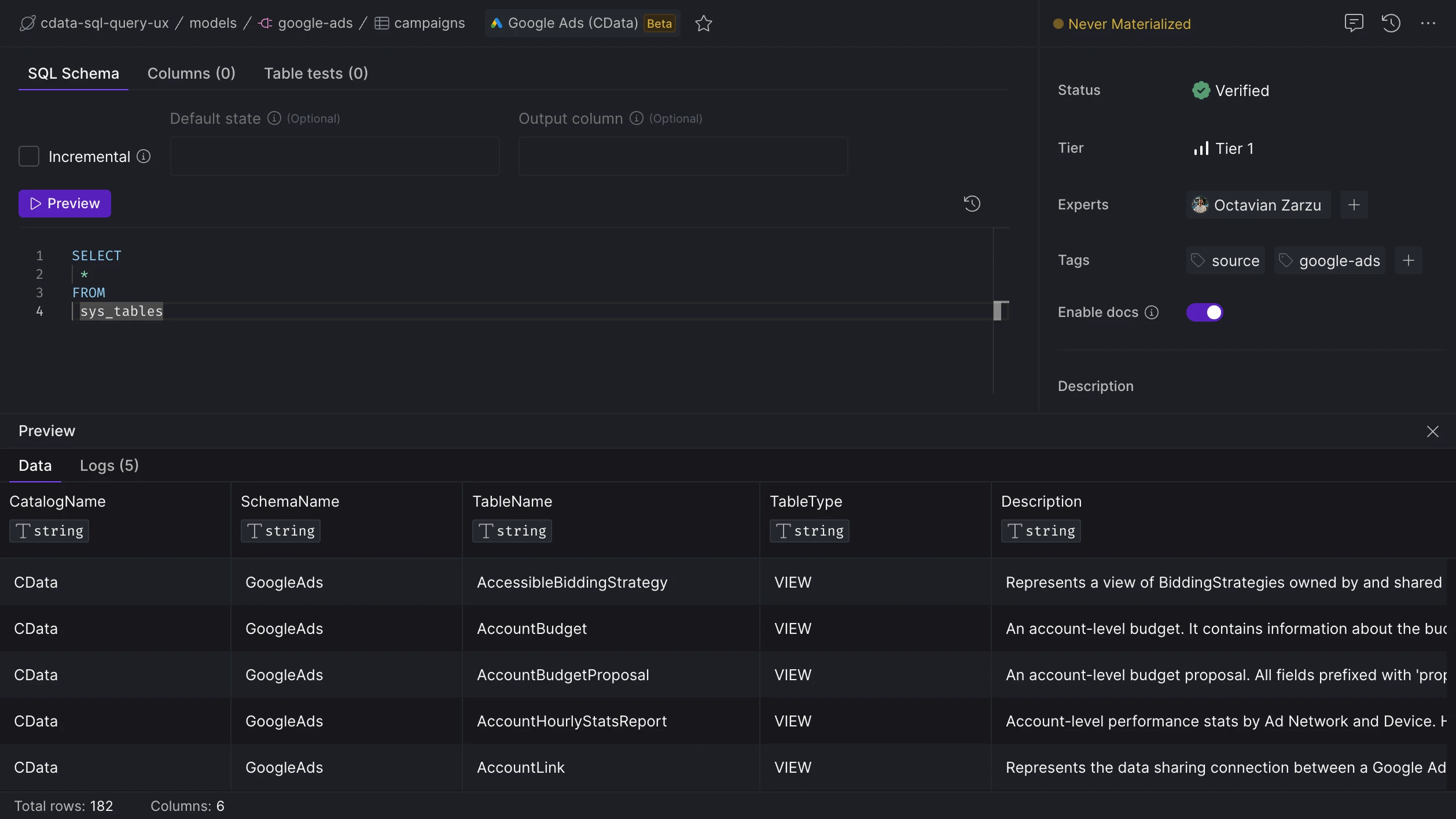
Discover source table schema by running queries again sys tables.
- Referring to the CData Python Connector documentation, specifically the REST Data Model section for the source you are interested in. For example, view the Google Ads' REST Data Model documentation for the Campaign view here (opens in a new tab).
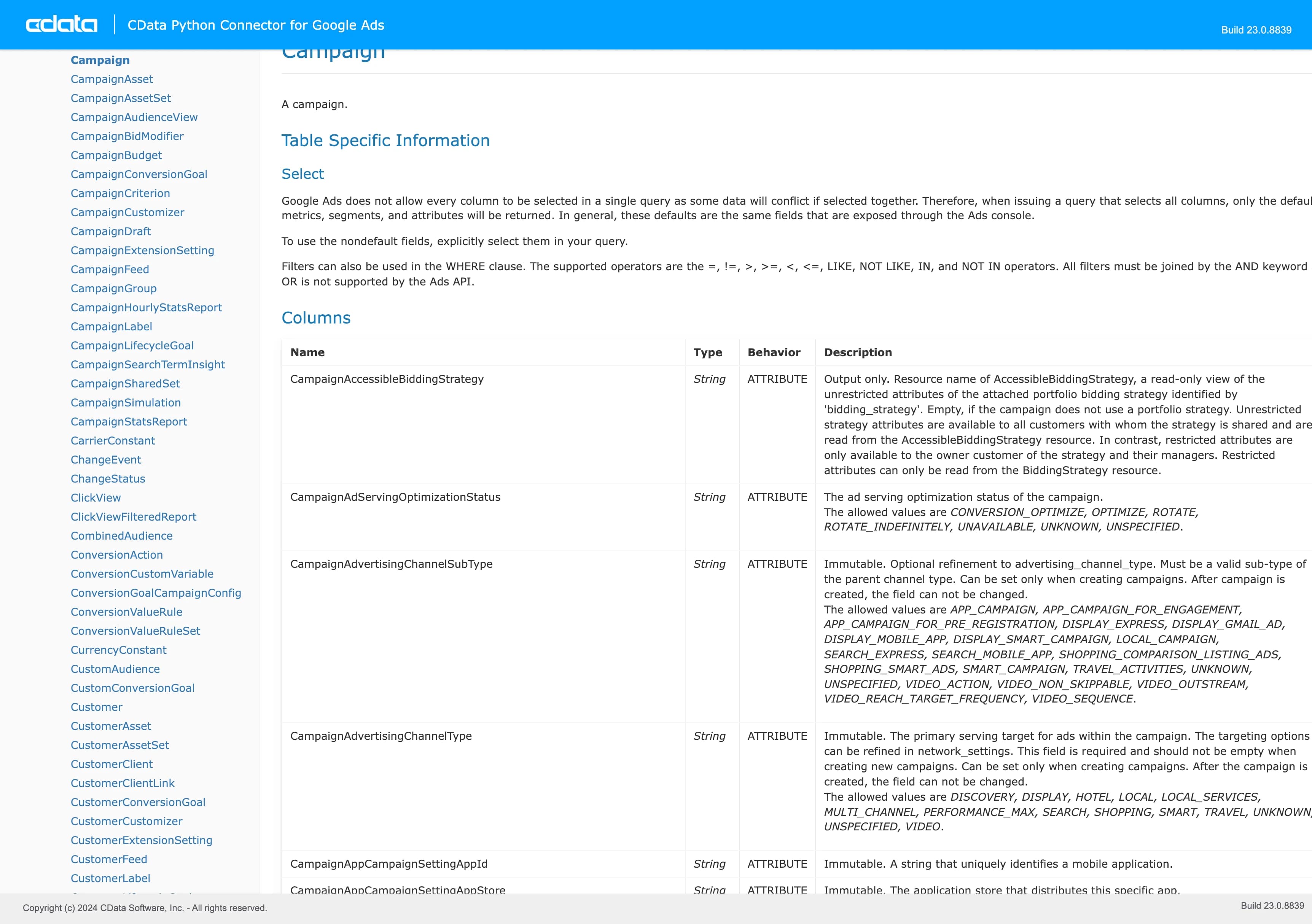
CData official docs.
Select data to ingest
You can ingest data using SQL statements only. Use the SELECT clause to specify which columns to ingest and apply filters with WHERE conditions; use subqueries if the data in your source table depends on data from another source table.
Example query:
Notes:
- Column selection: While
SELECT * FROM tableis useful for initial previews, avoid using it in the final model. Schema changes in the source table could introduce errors. Instead, selectively choose the columns to ingest and update your selection as the source schema evolves. Ensure these schema changes propagate downstream in your downstream models. - Preview limitations: Previews are restricted to 50 rows for the main query and 20 rows for subqueries.
- Transformation best practices: Minimize in-flight transformations. It is preferable to perform transformations after the data has been ingested into the data warehouse using models downstream.
- Set Operations: Operations like
JOINs,UNION, andEXCEPTare not supported during ingestion. Best practice is to ingest data from one source table at a time and perform complex operations downstream once the data is loaded into the data warehouse.
Commit and Build
Once you are ready to publish your changes, you should commit and build the asset to materialize it.
When you commit your changes, two types of files are saved:
- A
.ymlfile that contains all the necessary metadata to create the new source connector asset. This includes the source name, connection details, tables in scope, and other meta-related information. - A
.sqlfile for each source table configured, containing the SQL code used to ingest data.
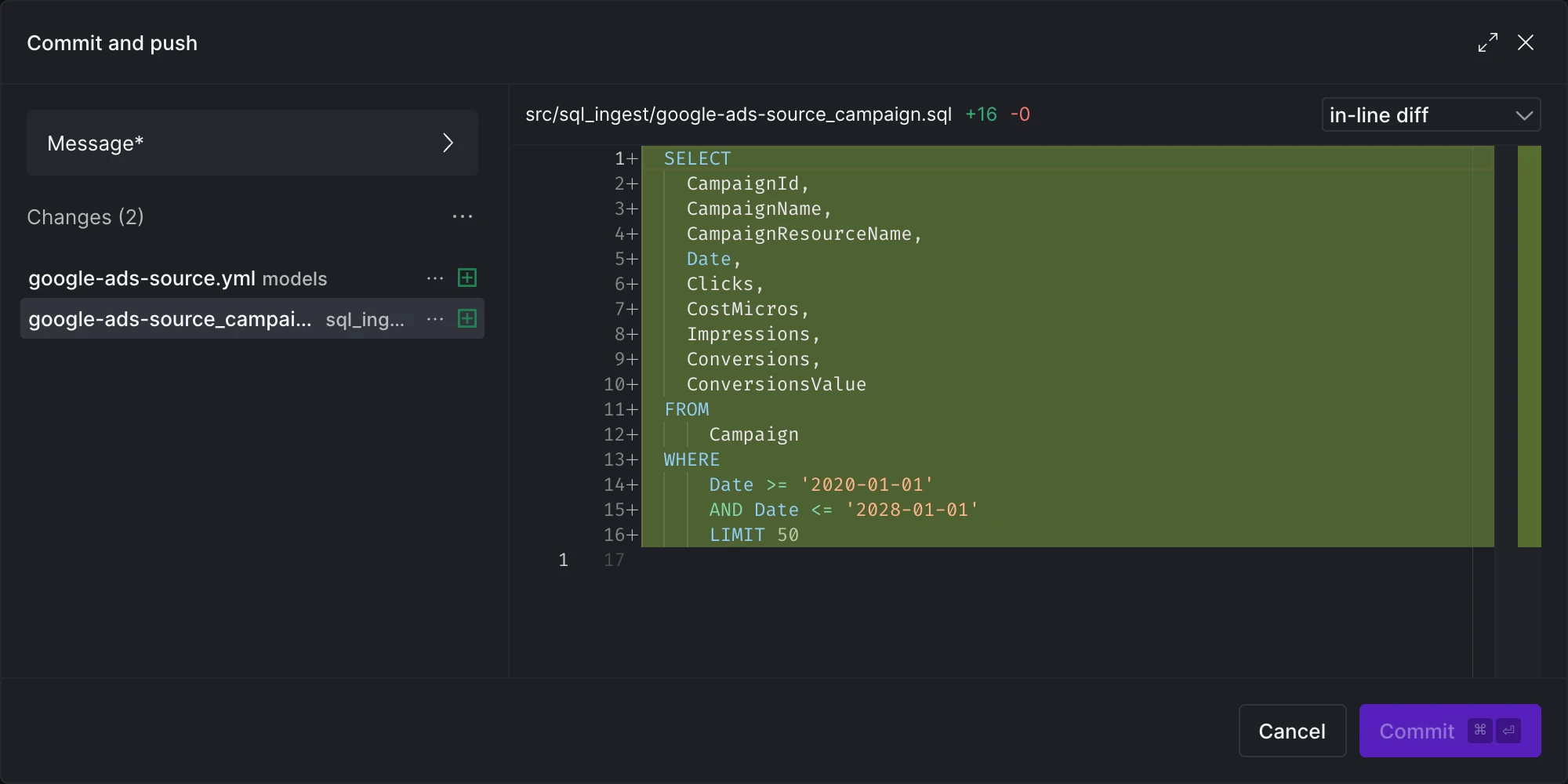
Commit source and tables.
To build the asset, navigate to Build History and select Trigger Build. This action will trigger a new build that will ingest the data into your data warehouse.
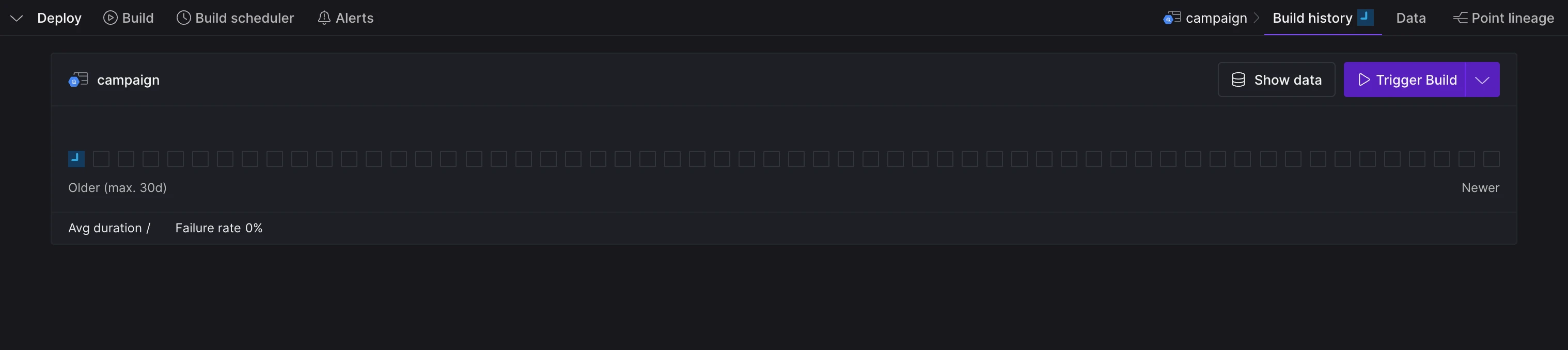
Trigger build for the new source and tables.
Incremental imports
CData table imports can be configured to incrementally pull only the data that has changed since the last run, based on a column or set of columns.
To configure a table import as incremental, follow these steps:
1. Enable Incremental Import.
- Check the incremental box in the UI to mark the table asset as incremental. 2. Specify the Incremental Column
- Identify the column that will dictate the incremental logic.
- Reference this column in your SQL model using the
'{{ var("STATE") }}'notation. For example:
3. Save the state column as part of the output columns for the asset.
The STATE value will dynamically adjust, ensuring only new data is fetched in subsequent runs.
4. Set a Default State value
Provide a default state for the first run. After this initial run, the STATE variable will be updated with the most recent data value.
5. Save the state column in the Output column.
While you can rename the state column, maintaining it as STATE simplifies configuration. If other column name is used, ensure the name matches the column identifier in the Output column.
After all configurations are complete, it should look like this:
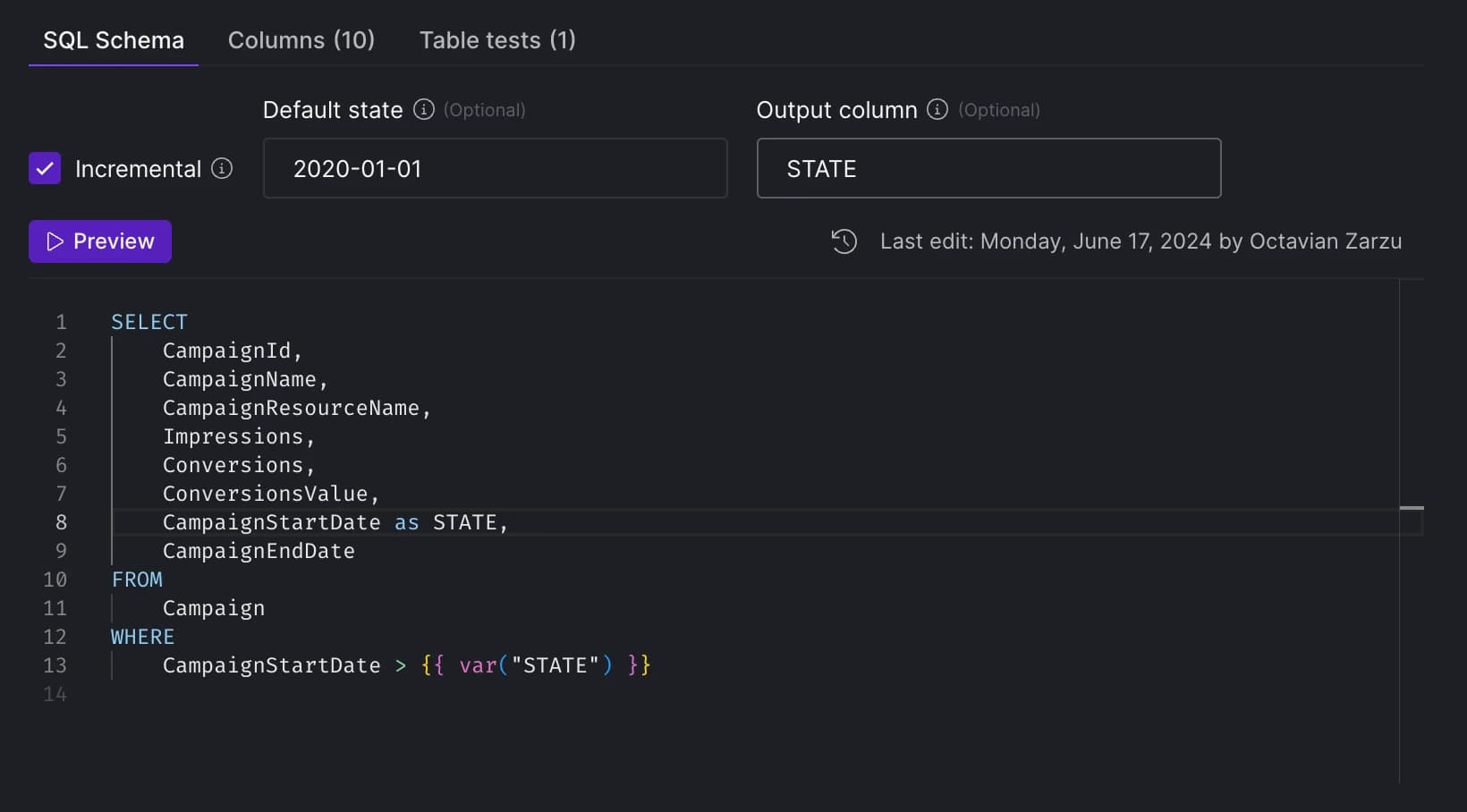
Example of a CData incremental source configuration.
6. Commit and Build.
Similarly to a full refresh job, commit the changes and trigger the build to apply the new configuration.
FAQ
How is the STATE value derived?
The STATE value is updated at each run, allowing you to dynamically build filters for your imports.
It is currently calculated by taking the first value from the result set of the job. To ensure accuracy, it is advised to add an ORDER BY clause to your query to sort the data (e.g., ORDER BY Created DESC).
In an upcoming release, the method to derive the STATE value will be adjusted to pull the MAX value rather than taking the first value from the result set.
How can I check the current STATE value?
You can fetch the latest STATE value by navigating to Build History, clicking on the last build, and viewing the Request Config. Example:
Example:
_10 .._10 "incremental_state": {_10 "parent_job_id": "7eb72758-42ee-4583-8ea3-929478101d99",_10 "previous_import_id": "7eb72758-42ee-4583-8ea3-929478101d99",_10 "previous_table_id": "7eb72758-42ee-4583-8ea3-929478101d99",_10 "state": {_10 "STATE": "2024-05-30 12:49:10.000"_10 }_10 },_10 ..
In an upcoming release, this information will be displayed alongside the Default State and the Output Column in the header of the job configuration.
How can I migrate to the new SQL interface?
To migrate from the drag-and-drop to the new SQL interface, follow this guide.
What are some of the best practices when setting up new CData connectors?
- Column Selection: Avoid using
SELECT * FROM tablefor final models due to potential errors from source table schema changes. Selectively choose columns to ingest and update your selection as the source schema evolves. - Transformation: Minimize in-flight transformations. Perform transformations downstream in the data warehouse after the data has been ingested.
- Set Operations: Avoid using JOINs, UNION, and EXCEPT during ingestion. Ingest data from one source table at a time and handle complex operations downstream.
Why is the preview limited to 50 rows?
Previews are limited to 50 rows for the main query and 20 for subqueries to optimize performance. When triggering a build, however, the full result set will be fetched from the source.