Sync modes
Get an overview of the supported sync modes for sources in Y42.
A sync mode determines how Y42 reads data from a source and loads it to your data warehouse. Y42 offers two sync modes for sources:
- Full imports
- Incremental imports
Full imports
When a table undergoes a full import, each job involves complete replication, where the existing table is replaced by a newly extracted table. This synchronization mode is particularly suitable in scenarios where:
- Records are permanently deleted from the source system.
- Incremental sync mode is not available for the source, or the table does not have an appropriate column for incremental sync mode.
Incremental imports
By utilizing incremental imports, Y42 effectively identifies new and updated data. This approach avoids replicating data already ingested from a source. If the sync runs for the first time, it's equivalent to a Full Refresh, as all data is considered new.
The type of incremental sync modes available varies depending on the source type: application or database sources.
Incremental imports in application sources
For all application sources, such as Facebook Marketing, Hubspot, Salesforce, or Shopify, Y42 supports syncing data in incremental append mode. This mode appends new and modified records, but will not overwrite updated ones. Due to this approach, duplicated records may occur.
Incremental imports in database sources
For database sources like Postgres or MySQL, you have two replication options available during the 'create secret' step when connecting to a data source:
- Standard: This method requires no additional setup on the source database side. However, a limitation is that it does not capture deletions from the source.
- Logical Replication (Change Data Capture): Many databases support capturing of all record changes into log files for replication purposes. A log consumer, like Y42, can read these logs and maintain the current log position to track all record changes resulting from
DELETE,INSERT, andUPDATEstatements.
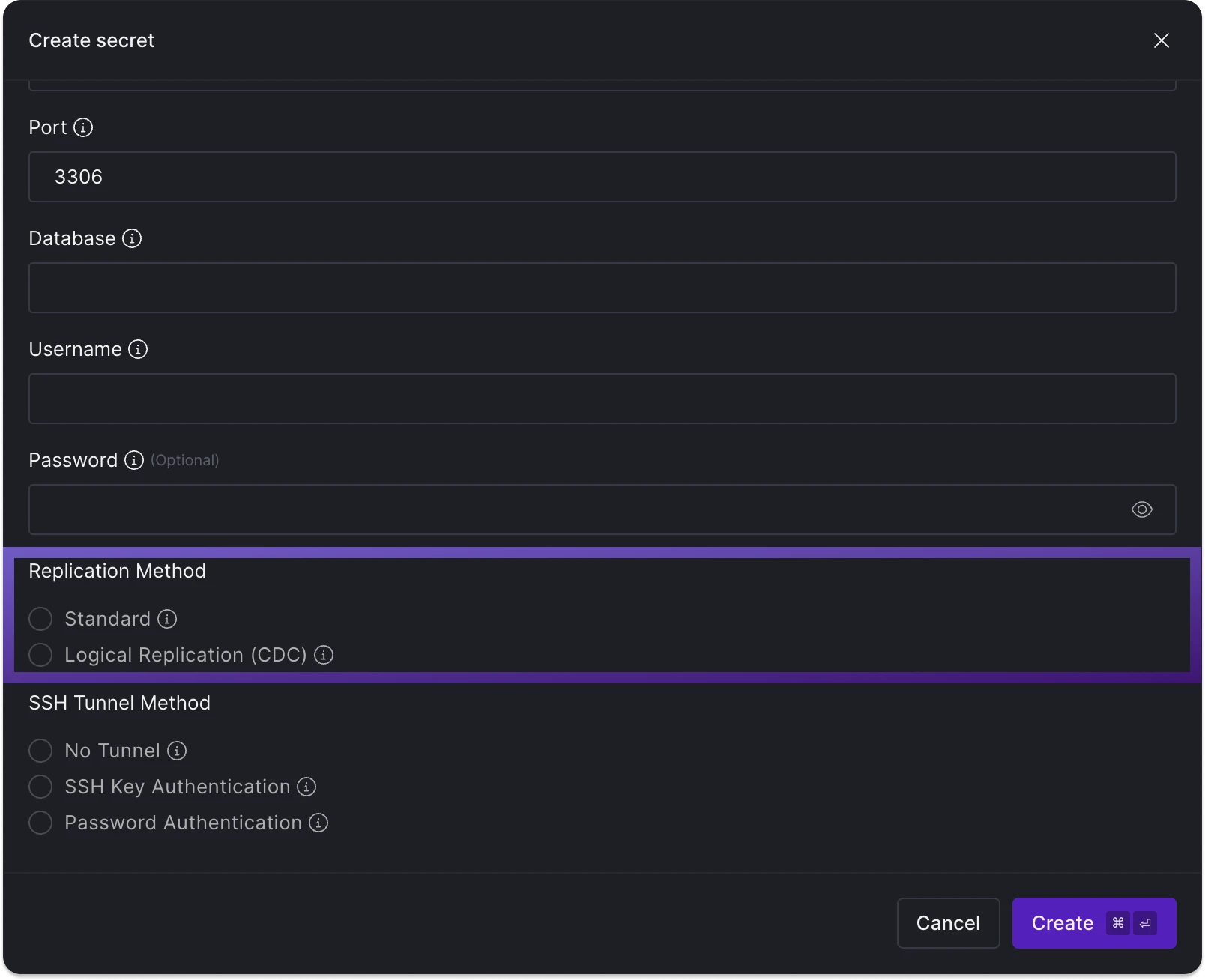
Y42's replication methods during the Create secret step.
Standard replication
Every new or updated record is appended to the existing data in the destination data warehouse, which may result in multiple copies of the same record in the destination. We guarantee "at least once" replication for each record present at the time of synchronization.
In cases where a table lacks an incremental or timestamp key for selection, each import will default to a full import.
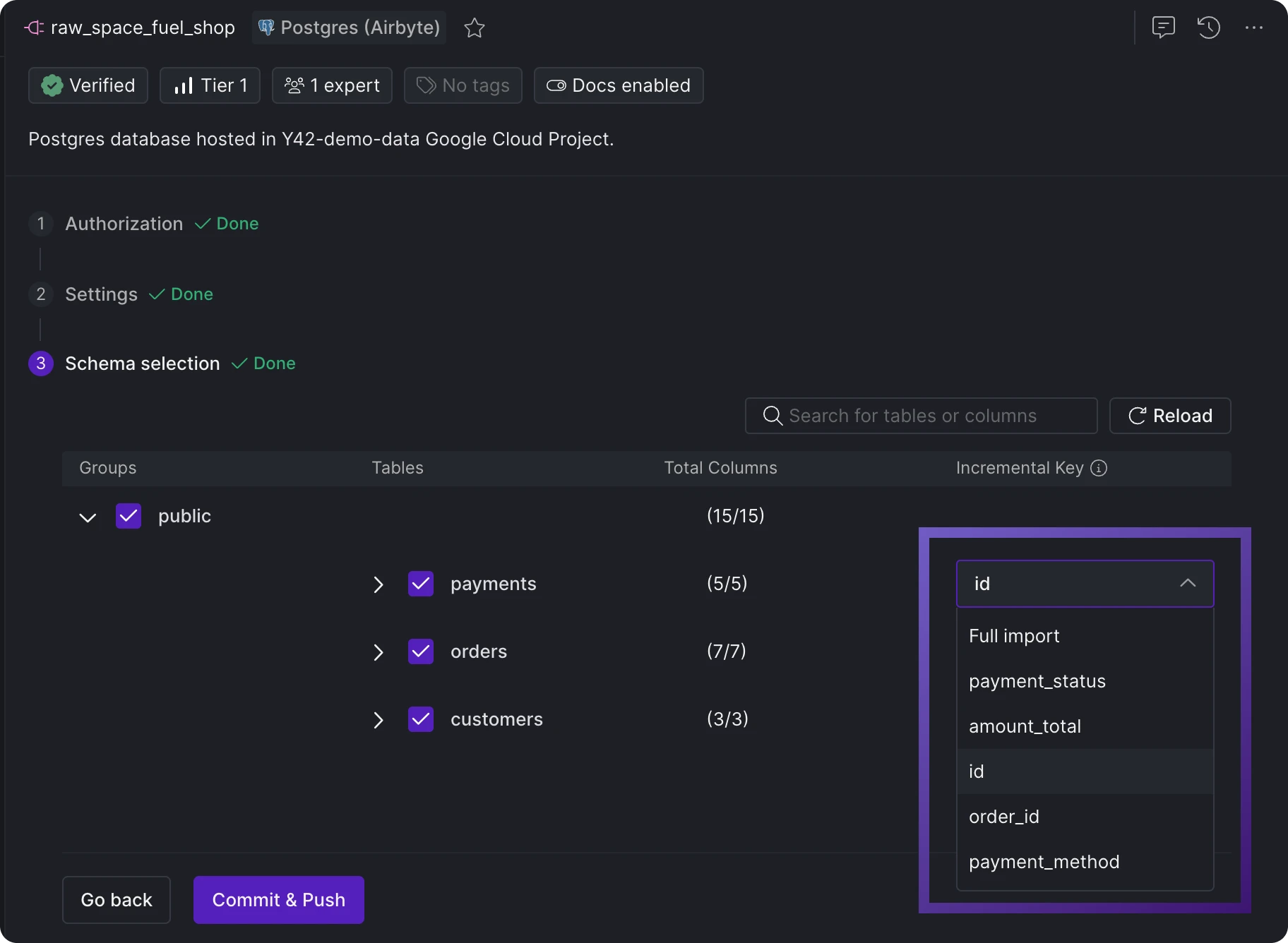
Incremental key selection for each source table from the input schema.
Logical replication (Change Data Capture)
The process for syncing in CDC is similar to that of non-CDC database sources. After setting a sync interval, regular syncs are initiated. We read data from the log up until the sync's start time, treating CDC sources not as infinite streams, but as bounded data sets. It's important to schedule these syncs frequently enough to process the generated logs. The initial sync acts as a snapshot of the current data state, effectively performing a Full Refresh using SELECT statements. Subsequent syncs will check the logs to identify changes since the last sync and update accordingly. Y42 maintains the current log position between syncs.
In a single sync, some tables may be set for Full Refresh replication and others for Incremental:
- When CDC is enabled at the source level, all tables marked for Incremental replication will utilize CDC.
- Full Refresh tables will follow the same replication process as non-CDC sources. However, these tables will still automatically include CDC metadata columns by default.
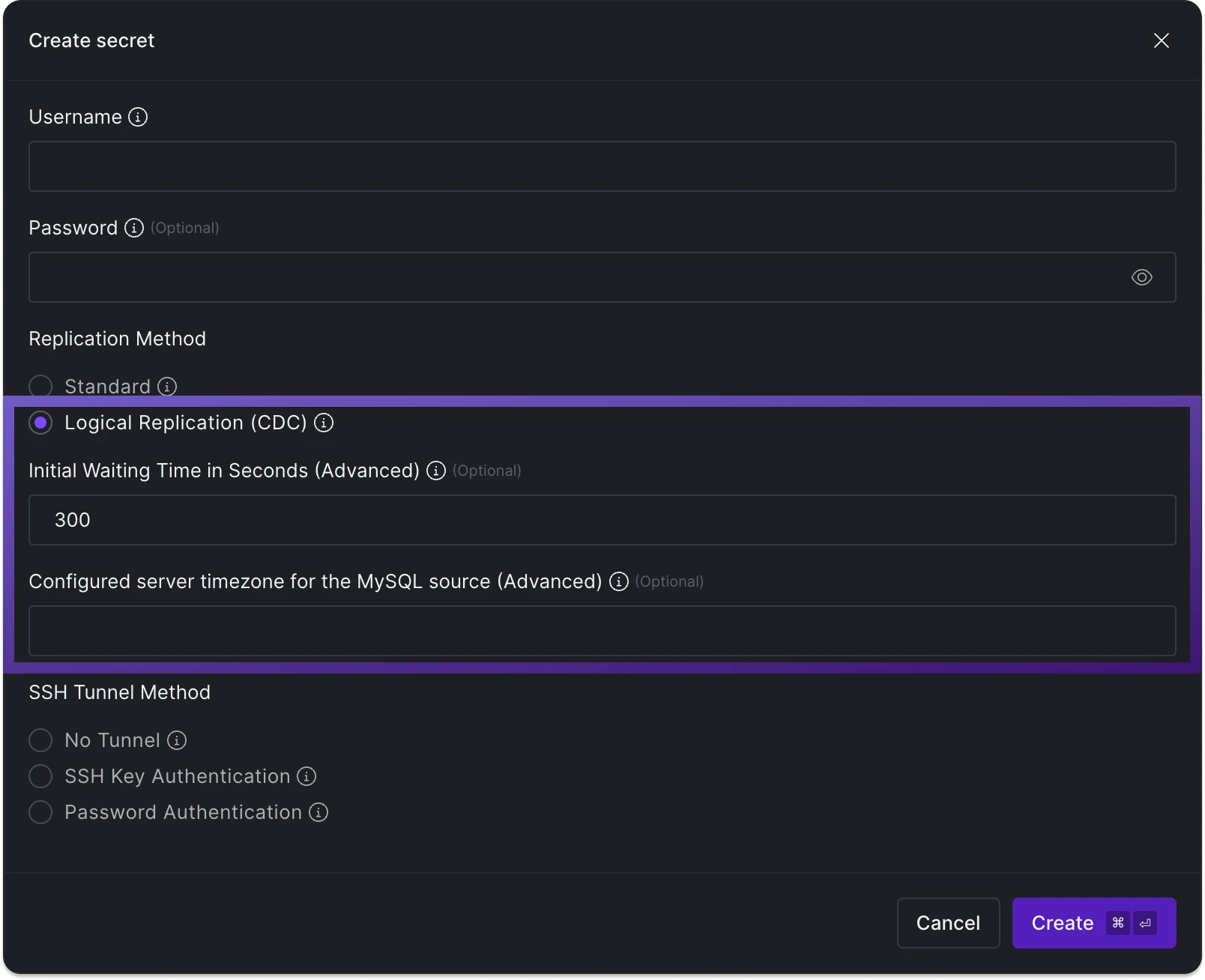
CDC configuration for MySQL.
De-duplication of records
To address the duplication of records that may occur, we recommend removing them in staging models. Below is an example of using a window function to retain only the latest record per id:
_10select_10 ..,_10 row_number() over (partition by id order by SystemModstamp desc) as row_num_10from {{ source('src_salesforce', 'Account') }}_10qualify row_num = 1
Additionaly, you can add column tests in your staging models to guarantee uniqueness in unique columns or IDs that are meant to be unique.
Run models incrementally
Downstream, you have the option to process data incrementally using the dbt incremental strategy. For more detailed information on this approach, you can refer to the documentation here.