We at Y42 are confident that every data team’s mission should be to produce reliable data tables efficiently (at a low cost and high performance) and make them consistently accessible to downstream users and applications to help ensure strong decision-making and further automate critical processes.
To achieve this goal, data teams need to have coherent, reliable, and efficient processes to generate production-ready data pipelines. However, as we outlined in our previous article, the modern data stack (with all its point-to-point tools) is not really accessible. And product management best practices, such as collaboration and governance, can’t just be “bolted onto” the stack, as they have to apply to all downstream and upstream processes to enhance DataOps in a meaningful way.
What’s more, the data industry is severely lacking a crucial asset that’s needed to help enable DataOps in any company: engineering power. Due to the high demand and low availability of data engineers, companies are often left with limited resources and fail to carry out comprehensive DataOps practices.
Therefore, it has been Y42’s core mission to fill this gap in the data industry with an efficient and scalable data solution to bring the world one step closer to taming the complexity that working with data entails. That’s why we set out to build the first Modern DataOps Cloud. Y42 now enables companies with the ambition to go beyond simple ad-hoc reporting to build production-ready data pipelines with a quick turnaround time,without heavy investments in data engineering.
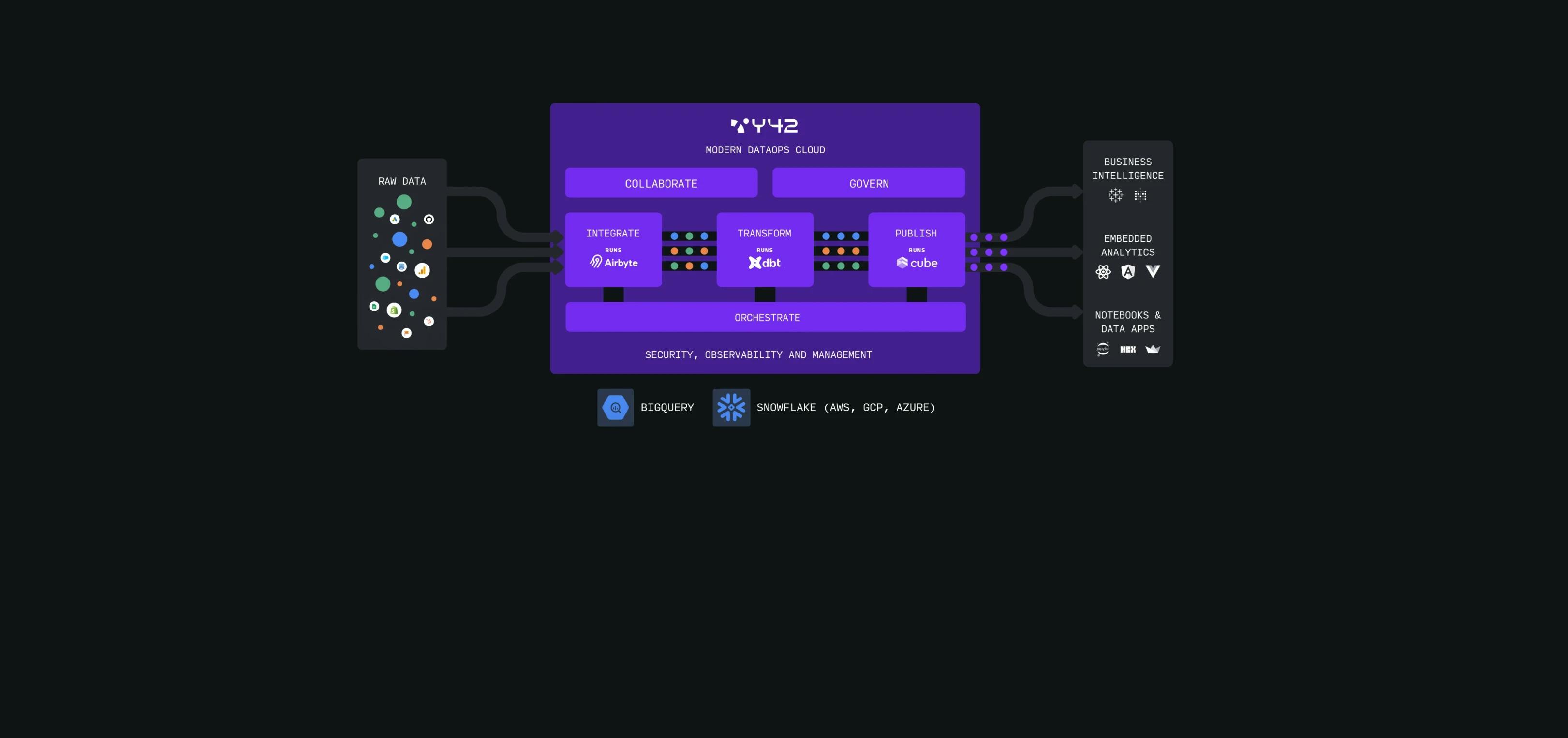
The Modern DataOps Cloud serves asmission control for a company’s data pipelines. Running on top of Snowflake and BigQuery, it enables organizations to deliver reliable and high-quality data to every downstream user or application. With Y42, companies are finally able to upgrade their often stovepiped data stack to an easily accessible and fully managed DataOps environment.
Y42 leverages the world’s most advanced existing open-source tools and technologies and embraces software engineering and product management best practices, making accessibility, collaboration, and governance the three guiding principles of our product.
Here’s how the Modern DataOps Cloud tackles the core problems currently present in the data tooling landscape, one by one.
Accessibility
Y42 natively integrates many of the modern data stack’s best-of-breed tools, resulting in one unified webapp, API, and CLI. This approach saves organizations precious data engineering hours stitching together and maintaining countless tools:
- Integrations: Managed Airbyte with 150+ integrations
- Orchestration: DAG-based workflow scheduler — interoperable and extensible with any other orchestrator and cloud tool such as Airflow
- SQL Model: Managed dbt Core overcoming some issues, such as the need to create a dataset for every branch in order for Git to work properly
- No-Code/Low-Code Model: Proprietary drag-and-drop SQL query builder to enable less technical users to build pipelines and explore data ad hoc
- Change Management: Managed Git server with features like pull requests and branch protection
- Headless BI: Managed Cube Dev providing a reliable metrics layer used across BI, data science, and operational applications — accessible through APIs
- Pipeline Visualization: Managed ECharts which enables users to quickly create powerful charts in Y42’s visualization layer
- API & CLI: Fully programmable pipeline through APIs, CLI, and webhooks
Governance
Data governance refers to the enforcement of rules that reduce the margin of error for working processes, transforming a team’s working style from reactive to proactive. This is possible due to the native integration approach in Y42, which spans across the whole data stack:
- Access Control: Role-based, multi-level access allows organizations to have full internal and external control of every data asset
- Asset Ownership: A system of ownership for better change management and accountability
- Data Contracts: Enforce semantic and relationship standards between data tables
- Data Tests: Eliminate errors and ensure high data quality by running data tests throughout the entire pipeline
- Templates: End-to-end templating to enforce standards across different pipelines
- Observability & Monitoring: Complete observability and monitoring of the whole pipeline through anomaly detection and alerts
- Data Lineage: Column-level data lineage that helps visualize the flow of data across the entire pipeline, identifying the root causes of performance and quality issues
Collaboration
Introducing collaboration best practices fosters knowledge sharing and alignment, supporting the co-creation of high-quality data pipelines. Y42 makes collaboration possible with the following features:
- Figma-like Canvas: Commenting function as well as sticky notes, text, and drawing capabilities available across the app
- Version Control: The world’s first Git engine that works with local changes in the browser and on the local machine
- Data Catalog: Enables users to quickly discover data assets, definitions, and metrics
The future of the data industry is now
Solving the core challenges currently present in the data space is Y42’s main goal. We’re here to revolutionize the data industry and the Modern DataOps Cloud is our first big bang.
We envision a future where every organization – whether it has one single data engineer, data analyst, or a whole data team – is able to deploy production-grade data pipelines efficiently and consume data in any downstream application to make better business decisions.
Since no one else in the data space is currently tackling the DataOps issues of inaccessibility, broken collaboration, and lack of data governance through the simultaneous implementation of software engineering and product management best practices, we at Y42 see it as our duty to help our customers bridge this gap.
The technical innovations we’ve outlined here are just the beginning. We can’t wait to keep expanding the capabilities of our product and continuously enable organizations to work with data in the most efficient and streamlined way possible.
But for now, see for yourself what the Modern DataOps Cloud is capable of.
Category
In this article
Share this article
