
Data analytics has traditionally been conducted in an ad-hoc manner, with data pipelines being built on an as-needed basis and run to answer specific business questions.
However, when data analysts, data engineers, or analytics engineers continuously build ad-hoc data pipelines for business stakeholders, a lack of consistency and standardization is bound to ensue. Just to name a few issues, this can lead to poor data quality, inaccurate data, and a lack of completeness, which can negatively impact the business decision-making process.
The shortcomings of ad-hoc data analytics
Building ad-hoc pipelines might seem like a sound solution to satisfy immediate data needs, but it’s not a sustainable long-term data analytics strategy. Here is an exhaustive list of the potential issues that arise from ad-hoc data analytics:
- Lack of consistency: Without a standardized approach, analysts may use different methods, models, or definitions to analyze the same data, resulting in different conclusions.
- Lack of reproducibility: Without a clear and consistent process for data analysis, it can be challenging to ensure that results are accurate and can be replicated by others.
- Lack of scalability: Ad-hoc data analytics may not be designed to handle the evolution of and increase in data requests that occur as an organization grows. Solving data requests when you only have ad-hoc pipelines requires constant manual re-production of the required base dataset. What’s more, goals and expected business value are subject to constant change in ad-hoc analytics, which hinders scalability.
- Lack of governance: Because they are typically built on an as-needed basis without a structured and standardized process, ad-hoc data pipelines lack proper governance and control mechanisms. They may not have been designed with data privacy and security in mind, and may be lacking proper documentation, testing, monitoring, and clear ownership and accountability.
- Lack of standardization: The lack of standardization will appear in different results. Not having a standard data pipeline could result in different conclusions each time a data analyst solves a data request.
- Lack of collaboration: Ad-hoc data analytics can make it difficult for different teams or departments to collaborate and share insights, as they may use different metrics and definitions of metrics.
- Lack of transparency: Ad-hoc data analytics can make it difficult for business stakeholders to understand and trust the results, as there may not be a clear process for data analysis and decision-making.
Adopting software engineering best practices can remedy these problems.
Why do we need to adopt software engineering best practices in the data world?
Adopting software engineering best practices in data analytics allows for the creation of maintainable and high-quality processes through automation and failure minimization. Some software engineering best practices include:
- Version control: By using version control software (e.g., Git), you can track changes to the source code, collaborate effectively, and roll back to previous versions if necessary.
- Audit: Auditing data pipelines and analytics can help you ensure compliance with data privacy and security regulations. It can also help you to better understand data operations and the decision-making process.
- Change management: A change management process allows you to understand how changes impact data pipelines and mitigate any risks.
- Abstraction and reusability: Abstraction is the process of breaking down data pipelines into smaller, reusable, and well-documented components. By designing data pipelines as reusable components, data engineers and analysts can save time and reduce costs while improving the scalability, reliability, and maintainability of pipelines.
- DRY philosophy: DRY stands for “don’t repeat yourself”. By following this philosophy, you can avoid duplicating code and logic, which optimizes warehouse costs and pipeline maintenance.
- Data tests: By testing data pipelines (e.g., schema testing), data engineers and analysts can minimize the chance of failure and fix any issues at the source.
- Observability: By monitoring, alerting, and logging your data pipelines, you can gain a better understanding of their performance and health and detect any anomalies.
Applying these best practices can improve the efficiency and effectiveness of data pipelines and operations. In practice, pipelines should be built using the CI/CD method, a fundamental aspect of modern software development.
What are CI/CD pipelines?
A CI/CD pipeline allows development teams to make code changes that are automatically tested and pushed out for delivery and deployment.
CI (continuous integration) is the practice of frequently integrating code changes into a version control system. This allows developers to detect and resolve conflicts early and ensure that the codebase remains stable. In data pipelines, this would involve frequently integrating new data sources, updating data loading, transformation, and consumption scripts.
CD (continuous deployment) is the practice of automatically deploying code changes to production as soon as they are deemed stable and ready. This allows teams to quickly and easily roll out new features and bug fixes. In data pipelines, this would involve automatically deploying updates to data pipelines and data models.
CI/CD pipelines can help data teams improve the speed, quality, and reliability of their data operations by automating repetitive tasks, enabling faster delivery of new features, and detecting and resolving problems early. It also allows for improved data management system monitoring and overview, which increases cooperation and minimizes development complexity.
Considering the benefits of software engineering best practices such as CI/CD and the limitations of ad-hoc analytics, the solution for ineffective data pipeline design is clear — building production-ready data pipelines.
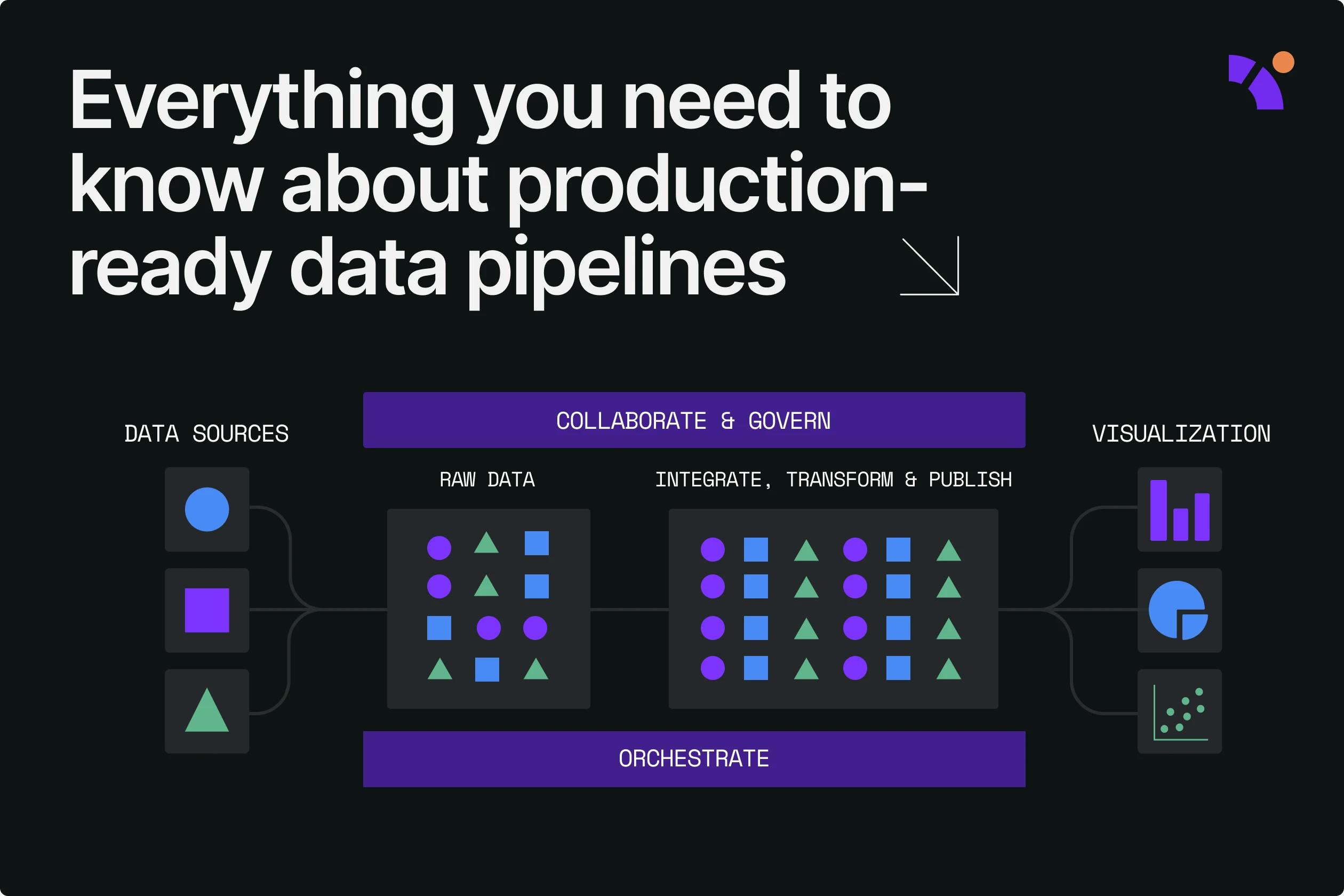
What is a production-ready data pipeline?
A data pipeline is considered production-ready when it has been fully tested for errors, continuously monitored, and optimized.
Production-ready data pipelines are encouraged because they ensure that data is consistently and accurately moved from source to destination. They automate the process of getting data into the hands of analysts and decision-makers, too. Additionally, production-ready data pipelines allow for easy monitoring and debugging and can handle data at scale. With these pipelines, data teams and organizations can use their data better and make more reliable decisions.
Why do you need to build production-ready pipelines?
Even though ad-hoc data analytics may seem more straightforward in the short term, several benefits come from constructing production-ready data pipelines:
- Consistency: Data is consistently and accurately moved from source to destination, which can improve the quality and reliability of the data.
- Automation: The process of delivering data to analysts and decision-makers is automated, which saves time and resources while reducing the risk of human mistakes.
- Scalability: Production-ready data pipelines are designed to handle increasing data requests and scale as data needs grow. Moreover, the goals and intended outcomes of the pipelines are not subject to constant change.
- Reliability: Handling errors and unexpected conditions can reduce downtime and improve the overall performance of the data pipeline.
- Governance: Data teams may achieve compliance by including data privacy and security in the development process. Moreover, access control, data ownership, data contracts, data lineage and cataloging, data quality, and data retention are all critical issues in governance that can be addressed with properly designed production-ready data pipelines.
- Reusability: Complexity, development time, and costs are decreased by using explicit, well-documented interfaces and components that may be reused across several pipelines.
- Monitoring: Having monitoring and alerts in place to track performance and detect issues simplifies troubleshooting and improving the pipeline.
- Deployment: Pipelines that are easy to deploy and test in production environments enable teams to quickly and easily roll out new features and bug fixes.
Differences between ad-hoc and production-ready pipelines
Ad-hoc and production-ready pipelines are two different approaches to data analysis. Here are some key differences between the two:
- Purpose:
- Ad-hoc pipelines: Typically used for one-off or exploratory analyses.
- Production-ready pipelines: Used to support ongoing business operations and decision-making.
- Standardization:
- Ad-hoc pipelines: Often unstructured and unstandardized because built on an as-needed basis.
- Production-ready pipelines: Follows a structured and standardized process by design.
- Reproducibility:
- Ad-hoc pipelines: May not be easily reproducible.
- Production-ready pipelines: Designed to be reproducible and ensure the same results can be obtained by different analysts.
- Scalability:
- Ad-hoc pipelines: May not be designed to handle increasing amounts of data requests.
- Production-ready pipelines: Designed to handle large data sets and scale to meet growing needs.
- Governance:
- Ad-hoc pipelines: May lack governance, control, and compliance over the data.
- Production-ready pipelines: Designed to meet relevant data privacy, security, accountability, and transparency regulations and standards.
- Automation:
- Ad-hoc pipelines: Often manual and time-consuming.
- Production-ready pipelines: Designed to be automated as much as possible.
- Monitoring:
- Ad-hoc pipelines: May lack monitoring and logging.
- Production-ready pipelines: Has monitoring and alerts in place to track performance and detect issues.
- Deployment:
- Ad-hoc pipelines: May not be easily deployable or testable in production environments.
- Production-ready pipelines: Designed to be easily deployable and testable in production environments.
Overall, ad-hoc pipelines are typically used for one-off or exploratory analyses, while production-ready pipelines support ongoing business operations and decision-making.
However, ad-hoc requests will always be part of a data team’s bread and butter. This is why they should and must be built on top of production-ready data pipelines. Using a well-built production-ready data pipeline as the foundation prevents data teams from having to reproduce the whole pipeline every time a report, dashboard, or analysis is requested.
The ultimate goal of production-ready pipelines is that their outputs can be used for different purposes — either established analytics (e.g., a daily sales reports) or ad hoc data requests.
How to build production-ready pipelines
Building production-ready data pipelines typically involves several steps:
- Understand the business’ needs and objectives, and define the pipeline’s data sources, destinations, and desired outcomes.
- Design the pipeline architecture, data flow, and data transformations needed to meet the requirements.
- Development and testing
- Implement version control to keep track of changes and ensure reproducibility.
- Write code to extract, transform, and load the data and test the pipeline to ensure it works correctly.
- Implement automated data tests to validate the data quality, completeness, and consistency.
- Governance and compliance
- Implement role-based access control to ensure that only authorized personnel can access the data.
- Define asset ownership to ensure clear accountability for data management.
- Establish data contracts with internal or external parties regarding the usage, storage, and handling of data.
- Keep track of a data lineage to understand the origin and movement of data through the pipeline.
- Create a data catalog as a centralized repository for all data assets, including metadata, data dictionaries, lineage, and lineage information.
- Implement a governance and compliance framework to ensure the pipeline complies with data privacy and security regulations and standards.
- Automation and monitoring
- Automate the pipeline as much as possible and use tools such as scheduled runs (orchestration) or event-driven triggers to run the pipeline automatically.
- Implement monitoring and logging to track performance, detect issues, and use alerts and notifications to advise the team of any problems.
- Deployment and optimization
- Deploy the pipeline to a development environment and test it to ensure it works correctly in a real-world scenario.
- Publish the verified pipeline in a production environment.
- Continuously monitor the pipeline performance, fix any issues, and optimize it for better performance and reliability.
Remember that software engineering best practices should be considered at all stages of the process.
Designing production-ready pipelines with Y42
Recently, there has been a shift from ad-hoc data analytics towards a more structured and standardized approach. This is known as production-grade analytics. This approach merges data analytics with software engineering to create production-ready data pipelines.
One key aspect of this approach is the use of CI/CD (continuous integration/continuous deployment) pipelines, which automate the process of building, testing, and deploying data pipelines. This allows for faster delivery of new features and early detection and resolution of problems.
Overall, production-ready data pipelines are necessary to create a more efficient, effective, and reliable data analytics infrastructure.
At Y42, we understand the importance of production-ready data pipelines in today’s data-driven world. That’s why we built the Modern DataOps Cloud and specialize in building reliable, scalable, and accessible data pipelines on top of industry-leading data warehousing tools like BigQuery and Snowflake.
Category
In this article
Share this article
