
What is a data pipeline?
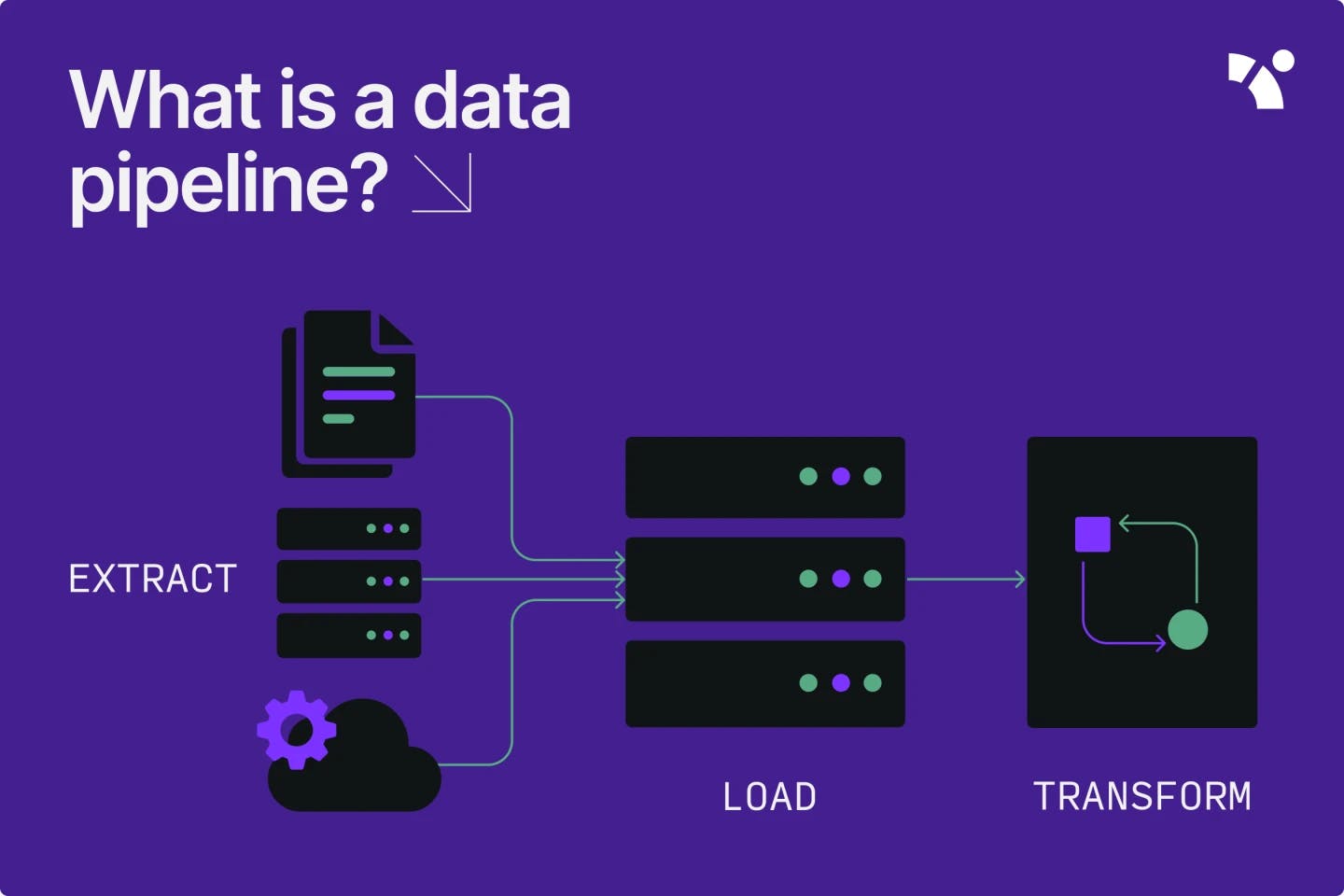
A data pipeline is a mechanism through which data is moved from one or multiple sources to a destination. The data could come, for instance, from a social media platform, like Facebook or Twitter, or a customer resource management (CRM) tool, like HubSpot or Salesforce. The destination of this data is usually a data lake, data warehouse, or analytics tool.
Why do you need a data pipeline?
In today’s digital world, the amount of data companies need to manage continues to grow exponentially. In 2021, humans created 2.5 quintillion bytes of data every day. It’s crucial, then, to find an efficient way to extract the insights from all this data that you need to grow your business.
Processing the vast amount of data that is currently available isn’t practical. Doing so would consume all of your time. In addition, as data becomes more complex, it gets increasingly difficult for you to obtain value from it.
A data pipeline automates the data ingestion, transformation, and orchestration process, making data accessible to downstream users and applications. With a data pipeline, you will spend less time ingesting data, manipulating it, creating reports, and responding to data requests. Instead, a data pipeline allows you to easily extract useful information so that you can get on with providing value to the business.
Controlling access to your data is also important. You don’t want multiple departments processing data in silos. This can lead to each department having different definitions for the same metrics, for instance. A data pipeline serves as a single source of information for your entire business, empowering teams to self-serve. This frees you up to implement and expand proper DataOps best practices without being bogged down with frequent data requests from multiple teams.
ETL versus a modern data pipeline
An ETL pipeline can be thought of as a specific type of data pipeline. An ETL pipeline is the process through which data is extracted from a source, transformed in a secondary processing server, and then loaded into a data warehouse or data lake. ETL stands for extract, transform, load. With an ETL pipeline, only the transformed data is saved in the data warehouse — not the raw data itself.
A modern data pipeline, on the other hand, may simply transfer the data from its source to its final destination without being transformed. The goal of the data pipeline is to move the data from one location to another for additional processing or visualization. The goal of the ETL pipeline is to transform the data as part of its movement from its source to its final destination.
The advent of cloud-based computing and storage has led to the ELT pipeline. An ELT pipeline switches up the order of the “T” and “L” steps, whereby the data is loaded into the data warehouse or data lake before being transformed.
What do you need to consider when building a data pipeline?
There are many considerations to keep in mind when building a data pipeline — the most important being the type of environment the pipeline should be built for (i.e., how the data is processed).
Batch
If you need to move large amounts of data on a periodic basis, a batch data pipeline may be right for you. You can set up the data pipeline to transfer the data at a frequency that best suits the needs of your business. However, you do run the risk of missing trends in between batch processing windows.
Real time
A real-time data pipeline may be more ideal for keeping up with the fast pace of the modern digital world. You can collect and move the data you need to respond to changes in customer demand within a matter of minutes.
Essentially, you need to select the environment that will work best for your data infrastructure and timeline. You can’t build a real-time pipeline when you only have batch data. Similarly, doing a batched pipeline is of no use if you need insights from real-time data.
Other things to consider are the data source and the tooling. The origins of both batch and real-time data can be cloud-native or on-premises, and the pipeline tools for both can be either open-source or commercial.
What are the components of a data pipeline?
A physical pipeline brings water from a river or lake to your home. The river or lake can be thought of as the source or origin of the water, while your home is its final destination. A water company purifies the water at a local processing station before sending it to your home.
You can think of a data pipeline in a similar way. A data pipeline takes data from its source, processes it, then sends it to its destination for your business to use to gain insights.
There are many components that make up a data pipeline. Let’s dive deeper into each one.
Source
The data can come from a wide variety of places. An application or data storage system typically serves as your data source, such as a social media platform, like Facebook or Twitter, or a CRM tool, like HubSpot or Salesforce.
Destination
The processed data can be sent back to the data warehouse, data lake, or business intelligence (BI) application. In addition, the processed data can also be sent to operational tools and applications (such as a CRM system) in a process called reverse ETL.
Data flow
The movement of the data from its origin to its destination is referred to as the data flow. Two common types of data flow are ETL and ELT.
ELT is faster than ETL, as no secondary processing server is required. ELT uses more storage space than ETL, since both raw and transformed data are stored in the data warehouse. However, since the raw data is uploaded to the data warehouse before being transformed with ELT, it can be re-queried infinitely, which contrasts with ETL.
Storage
At each point along its journey, the data needs to be stored before moving on to the next stage. It could be stored in a cloud data warehouse, like Snowflake or BigQuery. The evolution of cloud resources has drastically reduced the cost of data storage. As a result, the ELT data pipeline, where data is loaded into the data warehouse before being transformed, becomes an increasingly viable option.
Transformation and modeling
Just like water companies process water to make it drinkable, data also needs to be processed before it can be consumed. In a data pipeline, this step is known as data modeling — the art and science of transforming raw data into human-usable metrics that reflect the performance of your business. Data transformation refers to the process of joining, aggregating, or casting your data into a more usable form.
Orchestration
Data orchestration streamlines the execution of your data workflows by creating automated dependencies between your data pipeline’s components. Using data orchestration, you can schedule when batches get processed on a set frequency or based on a specific event.
Visualization
Visualization allows you to represent the data processed in your pipeline in a graphical format (such as in charts, dashboards, and reports) using BI tools. This enables you to translate data insights into compelling and actionable communications, telling the story behind the data.
Reverse ETL
With reverse ETL, the data is exported from the data pipeline or data warehouse to an external application or operational tool, such as Google Sheets or Salesforce.
Monitoring
Monitoring allows you to observe the data as it moves through the data pipeline. For instance, data tests are used to confirm the quality and integrity of your data. A good monitoring system will alert you if there are any failures, inconsistencies in the data being processed, or hiccups in completing any parts of the process.
Tools
The tools are the unique technologies used to build the data pipeline and to enable the movement of the data from source to destination.
What are the key features of a modern data pipeline?
There are many features to consider when selecting a data pipeline that works best for your business. A modern data pipeline improves the way you ingest and transform data to make it more accessible to downstream business users without slowing you down with cumbersome processing. Let’s explore these key features in more detail.
Scalability
The explosion of data shows no signs of slowing down, so your data pipeline needs to be able to scale with the growth of your data. You can enjoy full scalability by hosting your data pipeline in the cloud.
On the cloud, modern data pipelines can run several workloads simultaneously. It’s much easier to scale your data pipeline based on usage when it’s running on the cloud. An on-prem data pipeline would be more costly and involve purchasing and setting up additional physical servers to match user demand.
Flexibility
Additionally, a cloud-based data pipeline allows you to quickly spin up additional computing and/or storage resources when you need them. You’re no longer confined by being on-premises. As quickly as you can spin up resources on the cloud, you can also deactivate these resources when they are no longer needed. In this way, your cloud-based data pipeline will have superior flexibility over an on-premises pipeline.
Reliability and availability
You can’t afford delays in processing data through your data pipeline if you want to stay competitive. Your data pipeline needs to be reliable and available. Modern data pipelines feature a distributed architecture that safeguards them from disruptions. This cloud-based architecture switches your data pipeline workloads over to the next available cluster in the event of any disruptions, allowing critical business data to continue to be accessible by the teams that rely on it.
High data integrity
Another feature of modern data pipelines is how well they combat data loss or data duplication. Modern data pipelines have checkpoint features that ensure that data is only processed once. These checkpoint features also prevent data from being missed altogether. High data integrity allows you to glean more accurate insights from your data pipeline.
Intuitiveness
Modern data pipelines almost run themselves, since they are built with intuitive and user-friendly features. A well-built modern data pipeline allows both technical and business users to get the information they need from it, whenever they need it. Modern data pipelines also natively integrate with DataOps environments. This lessens the engineering effort needed to manage and maintain the data pipeline.
The ability to handle a variety of data
A modern data pipeline is not confined to processing just one type of data. It can handle many structured and semi-structured formats, such as SQL, JSON, XML, and HTML files.
Speed
DataOps principles have drastically reduced the time it takes to develop a fully functional modern data pipeline. For instance, DataOps automates many aspects of the pipeline development and delivery process by standardizing the process at each step.
Rapid data testing and the deployment of modern data pipelines is possible through the flexibility of the cloud, matching the pace of the business.
Build production-ready data pipelines with Y42
As data continues to grow exponentially in volume and complexity, you need an efficient way to readily provide data to business teams so that they can extract valuable insights from it. A data pipeline allows you to move large amounts of data from a single source (like social media) or many sources to a final destination (such as a data warehouse). You can increase controlled access to your company’s data by using a data pipeline. It will enable you to spend less time wrangling data, freeing you up to augment your DataOps practices.
With all the benefits of a modern data pipeline, you need an experienced partner to take your data to the next level. Y42 is the first fully managed Modern DataOps Cloud. Our mission is to help you easily design production-ready data pipelines on top of your Google BigQuery or Snowflake cloud data warehouse.
Category
In this article
Share this article
