
If you’re a data analyst or analytics engineer, then you are familiar with the process of receiving a request from someone in a business team. Typically, they give you the key metrics they need to track, then you go through the process of deciding which datasets are needed, what calculations need to be performed, and how to display that data in a user-friendly report or data visualization.
This can be a long and daunting process, and especially stressful if your colleague needs the report urgently.
But what if I told you there’s an easier and much quicker way to produce high-quality reports and visualizations? With data transformation, you can ensure key metrics are available to you when a report or visualization request arrives.
What is data transformation?
Data transformation is the process of joining, aggregating, or casting your data into a more usable form. Instead of dealing directly with raw data, you can create datasets that are clean, reliable, and automated to include key KPIs.
In this article, we will talk about data modeling and what it has to do with data transformation. We will also discuss the major benefits of transforming your data within data models and the types of models you can create. Lastly, I’ll include all our favorite tips for creating a clean transformation layer.
What is a data model?
A data model is multiple data transformations that reference each other, are strung together, and are compiled as if they were one block of code. It can be as simple as renaming column names or casting them to be a different data type. They can also be complex and include multiple common table expressions (CTEs) and subqueries.
Data transformations are typically written within data models using SQL, but can also be built using platforms like Y42, which offer no-code options and write the SQL queries for you under the hood. These SQL transformations can include the following operations:
- Joins
- Data type casting
- Column renaming
- Aggregations (count, sum, max, min)
- CTEs
- Subqueries
- Window functions
Anything that can be written in SQL can be written as a data transformation. The ability to automate complex operations on your data can lead to better quality data and faster results.
Let’s look at more of the benefits of data transformation.
Benefits of transforming your data
There are three main benefits to transforming your data in the form of data models:
- Speed
- Data quality
- Centralizing your company’s data calculations
Each of these advantages has the power to change the way your company uses its data.
Speed
First, data models created for core areas of your business can help you decrease the time it takes to complete a report or dashboard requested by a business user.
Data models help compile multiple key transformations on your raw data so that you have a clean dataset waiting for you. They reduce the need to manually run every piece of your transformation code, whether it exists in separate pieces or not.
Data models also eliminate the need to perform complex SQL logic directly within your reports or visualizations. There also won’t be a need to continually repeat code across multiple reports. Instead, the code you’ve already written can be used to create a dataset which then gets reused across multiple business functions.
Let’s look at an example. Let’s say you have multiple tables in your data warehouse that collect information about a customer’s order. Every time you want to create a visualization about customer orders, you need to join all of these tables together.
Instead of performing this same join within every order-related visualization, you can create an orders data model that does this for you. Then, instead of referencing the raw data tables in every visualization, you would reference this orders data model. This means you won’t need to write as much repeat code, which will increase the speed at which you deliver the visualization to your stakeholder!
Not to mention the fact that your reports and visualizations will also load much quicker. When there are a lot of transformations happening directly within the report, it can cause a long run time and lag when the user tries to access it.
Data quality
Writing your transformations within data models also increases code quality. Instead of needing to do basic cleaning directly within a report or visualization, you can do it within data models. Then, when you go to create a report, you are using data that has already been cast to the correct data type or name. This can be particularly useful when dealing with multiple time zones or poor naming standards.
I always make sure I create a style guide detailing how I want my data models to be written. I then follow these standards when writing my models.
For example, I like to rename all my columns so they are as specific as possible. This means I don’t get multiple “id” or “name” columns when I’m joining two tables. Changing these names in data models cuts down on confusion and eliminates the task of renaming them in downstream models. It is also helpful to cast all of your date columns to the same time zone in your upstream models to ensure they are accurately portrayed in your reports.
Centralizing data calculations
Centralizing data calculations is the most important reason for using data models. It happens way too often when different teams calculate the “same” KPI, yet they don’t match. Chances are, the teams each had a different definition for this KPI or were using different datasets. By creating data models which include these calculations, you are minimizing the things that can go wrong when you leave this up to individual business teams.
Data teams should be creating a data warehouse with data models that act as the single source of truth within the business. All teams should be getting their calculations from the same place. Data models allow you to decide on a KPI definition and then share it across multiple teams, ensuring they are all looking at the same numbers.
Tips for setting up clean data transformations
As an analytics engineer, I’ve learned the best ways to set up your data models through trial and error.
Here are a few of my tips!
Use data modeling layers
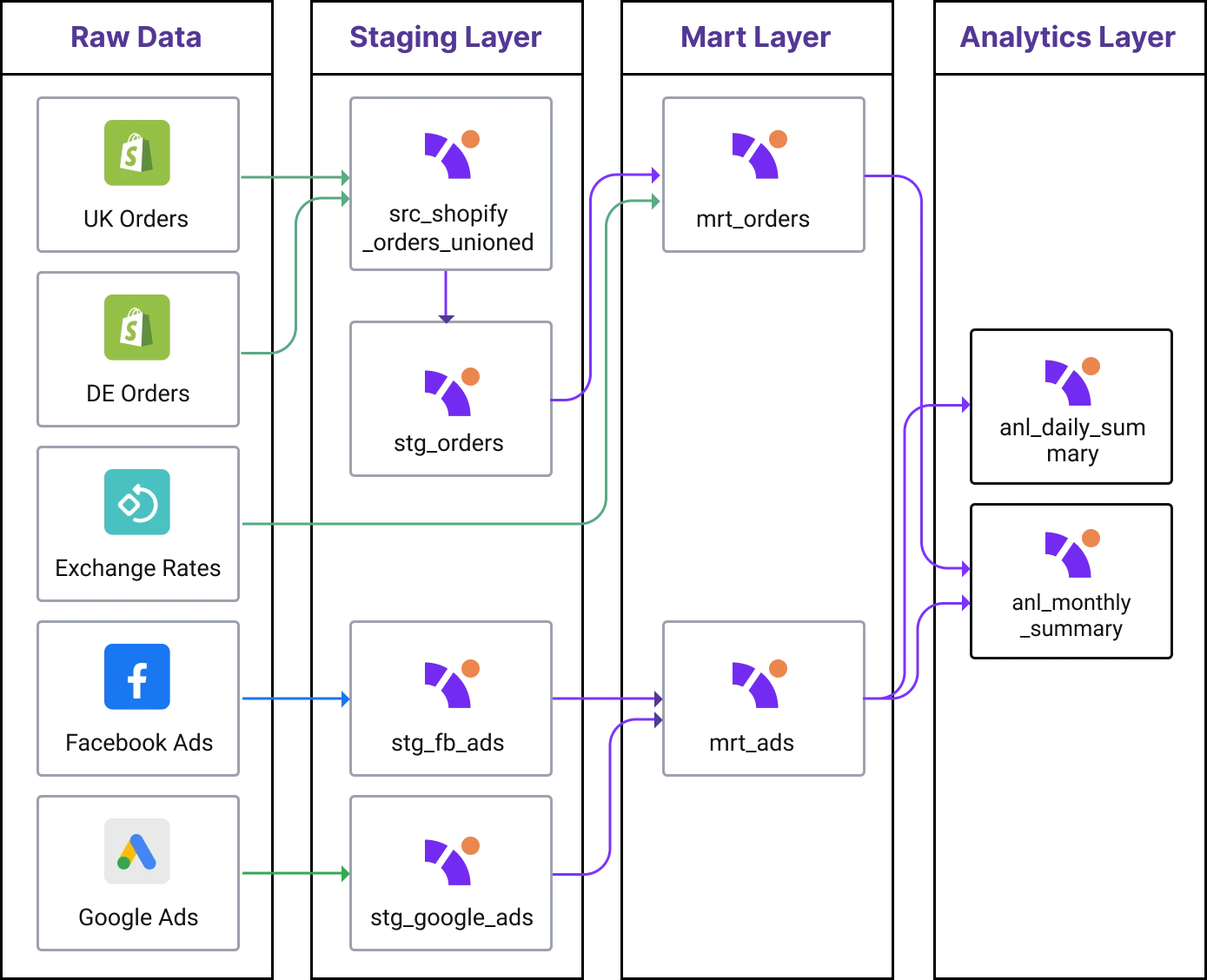
Be sure to separate your data models into source, staging, mart, and analytics layers. Each serves a different purpose in your overall data transformation strategy. By separating your transformations into layers, you are optimizing for speed and clarity. Your final models (including the code you used to build them) will be easy to reuse and read by everyone on your data team.
Start by creating a data transformation style guide
This is the very first thing I do when implementing data transformations in a modern data stack. Instead of doing everything as you go, set standards before you start the actual coding. Being clear about how your data models should look before actually creating them eliminates any confusion and minimizes the need for changes down the line.
Your style guide should include:
- How you would want to name your columns — camel case (i.e. orderDetails), snake case (i.e. order_details), etc.
- Rules for how you want your SQL to be written (answering questions like “Should I only use CTEs or are subqueries okay?”)
- Documentation standards for data models (“Will I comment on my code or have a separate document explaining the logic used?”)
The worst thing you can have is a bunch of data models that all follow different standards. This will make your data unorganized and impossible to work with, especially if there is more than one person on your team writing these models. Write your style guide and make sure everyone on your team is following it.
Standardize dates and time zones from the very start
Choosing a data type and time zone for all your data is imperative for keeping it accurate. This is one of the things that should be called out in your style guide. But, I think this is so important that I needed to explicitly state it as its own tip.
I’ve been in some painful situations where certain calculations in my data models didn’t add up. I spent a lot of time trying to discover the issue only to find that I was using two different time stamp types, which were messing up the joins in my model.
Don’t just assume every date or time zone is the same datatype. When I was working on this data model, I assumed all time stamps were the same. I learned that there are MULTIPLE time stamp types, but only after a lot of wasted time. Choose one from the start and cast every time stamp to that type in your staging layer. Be sure to document this in your style guide too, so anyone working on the data models knows to do this.
Make sure you decide on a time zone for all your time stamps. Different raw data sources have different standards for this, so it may be important to look at the API’s documentation. I recommend casting everything to UTC time to make time zone calculations easier. If you start with all of your timestamps in UTC time, you can then cast them to the desired time zone in the mart layer.
Data transformation transforms how companies work with data
Data transformation can feel daunting at first, but it will soon become second nature when you learn and implement some data modeling best practices.
Data transformation is the reason data models are so powerful for companies. Writing your transformations within data models decreases the time it takes to complete analytics requests, increases the quality of the data you are using, and centralizes calculations that are key to the business’s success. Luckily, companies like Y42 make the process of transforming your data and organizing it into data models seamless.
To learn more about data modeling best practices, check out this data modeling guide written by Y42’s own solution engineers.
Category
In this article
Share this article
