
When working with data as a data- or analytics engineer, our work is often guided by three distinct systems: the tracking of logical changes via Git version control, the materialization changes resulting from the code changes, and the handling of operational changes through environments. But what if these systems could be merged into one?
At Y42, we're introducing Virtual Data Builds – a solution that unifies the three management systems into one. This allows data engineers and analytics engineers to control all operational and logical changes exclusively through their existing Git workflows. Virtual Data Builds integrate seamlessly into your current operations, providing a cost-effective strategy for data change management. With Virtual Data Builds, you can deploy or roll back changes, and instantly create new virtual environments, without the need for creating physical environments or duplicating data. This not only significantly reduces storage and compute costs, but also provides the benefits of the dbt --defer feature (we’ll talk more about this below) with none of its added complexity, making the process easy to use.
What are data warehouse environments?
A data warehouse (DWH) environment refers to a specific setup or instance of a data warehouse, with its associated data, transformations, connections, and configurations. This can be thought of as the context in which your data warehouse operates.
In a typical software development process, multiple environments may be used to manage changes safely - such as development, staging, and production environments. Similarly, data warehouse environments are used to manage and test changes to the data warehouse setup - including changes to the structure of the data, the transformations applied, the connections used, and so on - before those changes are deployed to the production environment. Each environment, in effect, is a separate instance of the data warehouse, with different data and configurations.
The challenges with managing DWH environments
Managing DWH environments can be a complex task, as it involves ensuring that data, schema, transformations, and configurations are correctly synchronized across environments, and that changes are safely tested and deployed, often requiring deploying manually configurations, long-running CI pipelines, and code to physical schema synchronization.
This is particularly challenging when working with large volumes of data, as creating separate physical copies of the data for each environment can be resource-intensive.
Existing solutions and their limitations
Data teams have adapted various tools to manage DWH environments. For instance, data teams commonly use Flyway or Liquibase to manage changes to database schemas. This tool enables controlled and versioned application of scripts to databases, aligning them with the required changes of the application.
In addition to database schema versioning, data teams use Git for code versioning. This introduces another layer of complexity, as changes in the codebase often need to be synchronized with the database schema alterations.
To validate the impact of code or schema modifications, data pipelines are often rerun to backfill data. This process can be resource-heavy and time-consuming, especially with larger datasets.
Some analytics databases, like Snowflake or Bigquery, offer features such as zero-copy cloning or table clones to simplify the management of database environments. This feature allows you to create copies of databases for testing or experimentation without duplicating the underlying data, saving on storage costs and time. However, this requires manually creating clones and setting permissions. More importantly, when it’s time to deploy the changes from the dev clones into your production environment, there is no straightforward way to merge the changes without re-running your DAGs.
dbt introduced the --defer flag to mix production and development data assets by relying on a snapshot of manifest.json. While this method may work for experimenting in lower environments, it comes with a set of challenges and cannot be reliably used for deploying changes to production. The environment and assets management becomes an afterthought in dbt. What if the asset was refreshed in production in between the time you deferred it and the time the PR was approved? Even if that is not the case, will you reference the dev asset in your production pipeline to avoid rebuilding the asset again in production? What happens the next time you want to defer the asset – do you defer the one from dev now? How can you promote changes without lengthy-rebuilding cycles of each asset changed? The state:modified method doesn’t help either as this is simply just a method to run a subset of affected assets instead of all of them.
While SQLMesh's Virtual Environments improve data warehouse management, they introduce a new tool with a new syntax to manage environments (sqlmesh plan) instead of using an already-established system like Git for operational changes. As a user, you have to run sqlmesh commands to manage operational changes alongside managing your code changes.
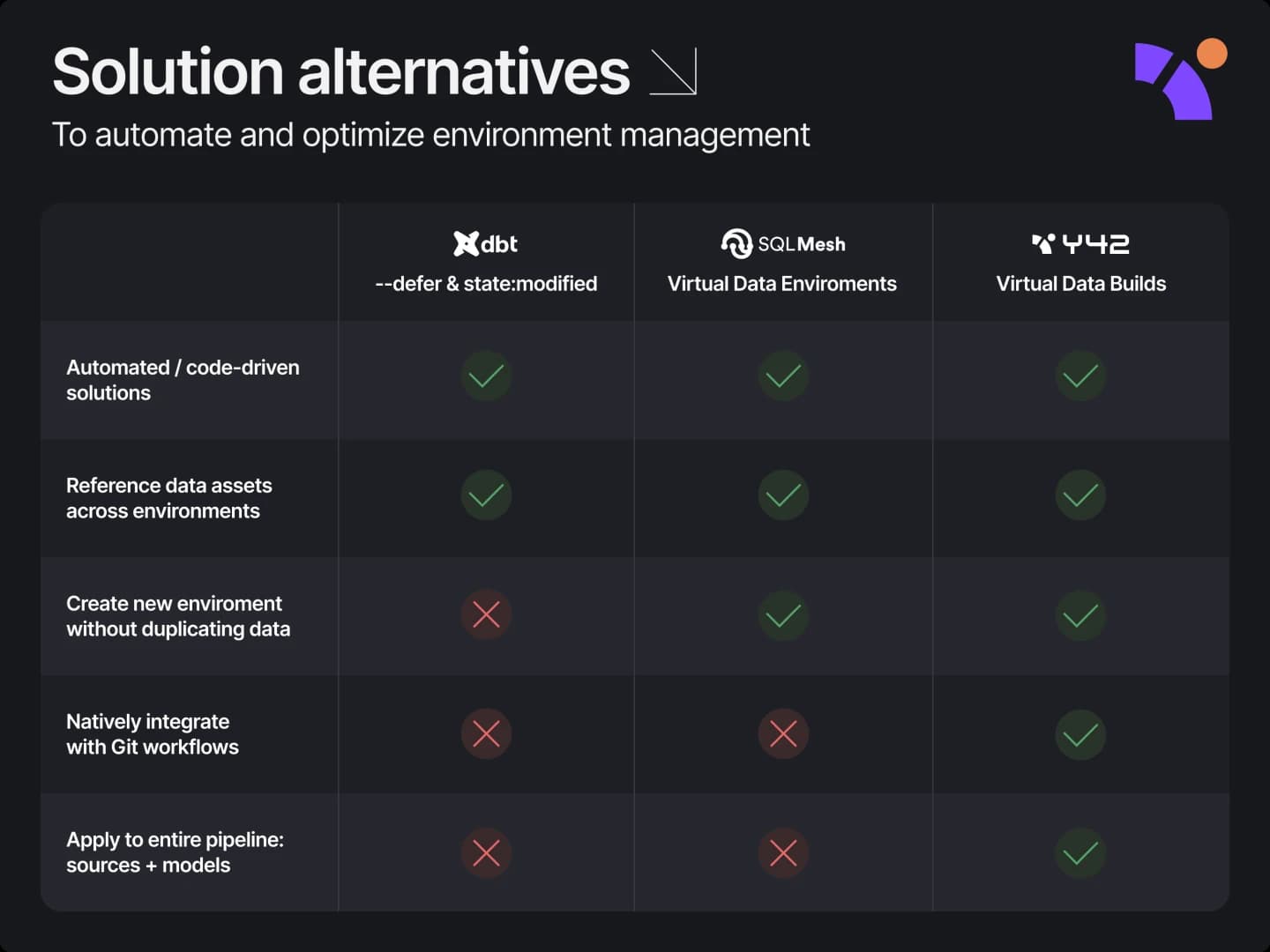
Other Git-based solutions are available, but they are not designed for data warehouse use cases. For instance, LakeFS is a notable solution for data lake scenarios. As an open-source platform, LakeFS brings Git-like capabilities to data lakes. This allows for the creation of data lake branches, isolated changes, and version commits, much like a traditional Git repository. Despite its significant benefits in simplifying data versioning and facilitating experiment reproducibility, LakeFS is primarily focused on raw data versioning. It doesn't inherently address the complexities associated with managing and synchronizing transformed data across various environments, a critical aspect of data warehouse management. In the realm of Online Transaction Processing (OLTP), Dolt is a notable player, whereas for Data Science (DS) and Machine Learning (ML) use cases, Data Version Control (DVC) is a preferred solution.
A DWH environment for every Git commit
Given all the challenges mentioned above, what if we could synchronize our codebase, database schema, and data from a single hub, seamlessly integrating all changes? What if this system blended into our existing workflow using Git to track code changes while maintaining an alignment with our data warehouse, without necessitating any extra steps on our part?
Imagine a system where every Git commit corresponds to a specific data warehouse snapshot – a new data warehouse environment. If we revert a commit, the data warehouse also reverts, aligning with the previous commit. If we merge changes from a branch into main, the system intelligently applies those existing branch changes into the production environment, sidestepping a lengthy, error-prone deployment process.
Such a system would drastically simplify the change management process, storage and compute resources. Having every codebase state matching a data warehouse state ensures that code changes are instantly mirrored in the DWH, thereby maintaining strict consistency between your code change and the DWH. Furthermore, as we will explore in the following section, a Git-dependent solution reduces the need of always duplicating data for new environments, and therefore, diminishing the storage and compute costs.
Introducing Virtual Data Builds
Virtual Data Builds are a solution designed to streamline the deployment and rollback of your data warehouse changes by focusing on the codebase, effectively sidestepping the complexity of managing multiple environments.
The way they work is that Virtual Data Builds instantly spin up new environments behind the scenes for you, all without duplicating data or requiring any action outside of the standard Git operations. Changes to your DWH are tracked similarly to how Git tracks your code changes.
Virtual Data Builds function on two levels:
- Internal schema: Stores all materialized variations of your data assets.
- Public-facing schema: Contains views that point to the most recent variation of any asset in the internal schema
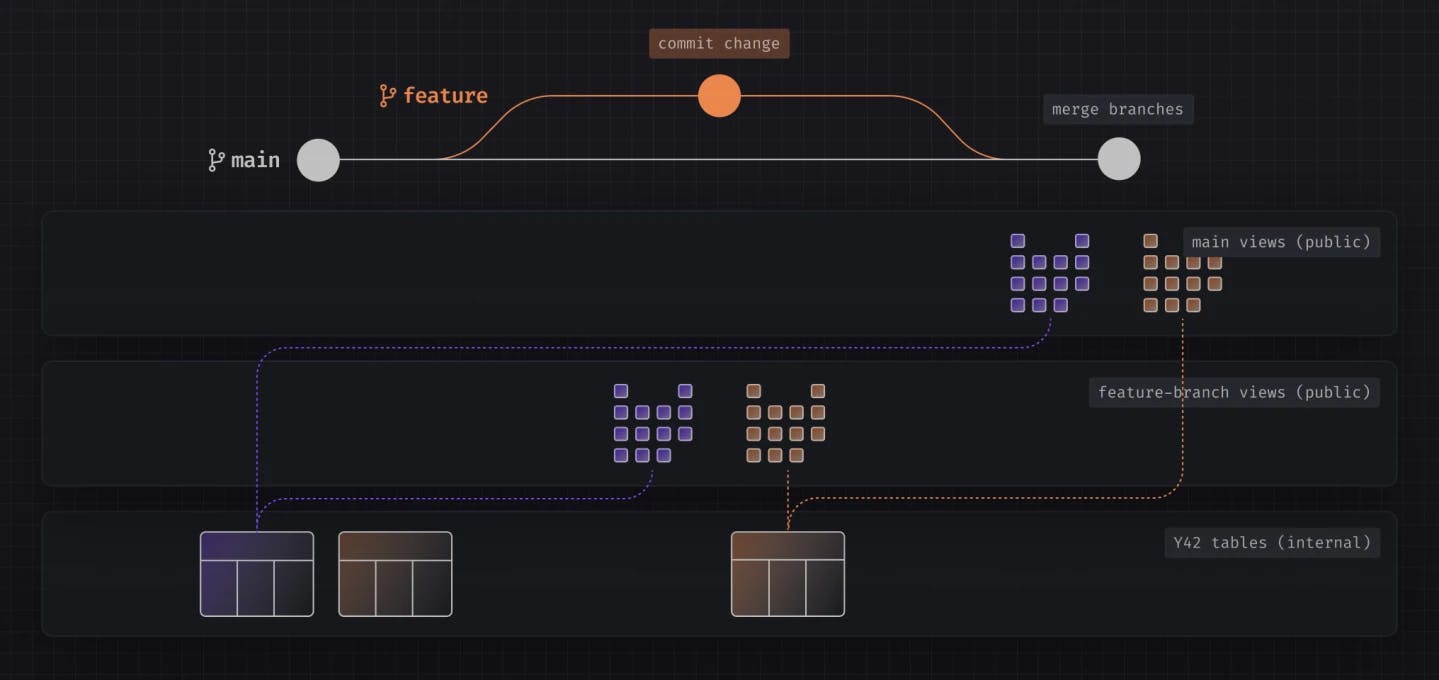
Moreover, we incorporate branch level deployments in our process. For each branch that the user opts to deploy, we automatically generate a schema and the respective datasets. These schema / datasets are views that point towards the appropriate physical tables, using the Git state of the respective branch.
In essence, Virtual Data Builds act as an advanced system managing the swapping of view pointers based on every Git interaction.
The creation and maintenance of both schemas are handled by Y42. Virtual Data Builds assist in establishing links between the different variations of materialized assets in the internal schema and the views in the public-facing schema, using standard Git commands.
Here are some scenarios for better understanding:
- Committing Changes: Upon committing changes to one or more assets in Y42, a new physical variation of the asset(s) is created in the internal schema. The pointers in the public schema are automatically updated to reflect the new state of your codebase, referencing the latest materialization of the assets.
- Reverting Changes: When you revert changes (at the commit or individual file level), the public schema views point to the previous materialization of the asset, eliminating the need to recreate the tables.
- Merging Branches: Merging a feature branch into main? Y42 automatically updates the public schema view(s) to reference the existing physical table(s) from the recently merged branch - therefore, no need for table recreation.
- Upstream Changes: If a modification impacts other assets downstream, Y42 will notify you and prompt the recreation of all affected assets downstream. This ensures the state of your codebase remains synchronized with the data warehouse assets. When changes are promoted to the main branch, the system instantly swaps the views’ pointers in the public-facing schema.
- Creating New Branches: This action does not incur extra storage or compute cost as new logical replicas of the assets point to the same underlying data in the internal schema. This provides you the capability to directly interact with production data when developing without jeopardizing your production assets.
In Y42's system, every data asset has what we call a lineage hash. This unique identifier encapsulates the asset's configuration and dependencies, linking it to all the upstream operations and configurations that have contributed to its current state. As such, the lineage hash is a property of an asset that changes when upstream modifications occur. For instance, if there's a change in an upstream table configuration, Y42's smart system recognizes this change by identifying a shift in the lineage hash of the downstream assets. As a result, all affected assets are automatically marked as stale and are rematerialized from scratch to incorporate the changes. This smart, lineage-based tracking system allows for precise and efficient handling of modifications across different branches, guaranteeing data integrity and consistency. This all happens automatically, removing the need for manual tracking and re-computing, thus saving time, computational resources, and preventing potential errors.
Virtual Data Builds are essentially offering a sophisticated system that elegantly manages views’ pointers, efficiently linking your codebase changes with your data warehouse environment.
Note: In Y42, it isn’t just the transformation layer that’s Git-managed — it’s actually the entire pipeline. This includes things like the configuration of your data connectors, orchestrations, alerts, and access control rules. However, there are only two types of assets that are physically materialized in the data warehouse and in scope of Virtual Data Builds: sources and models.
How Virtual Data Builds work?
But how exactly does this process work? Below, you'll find an in-depth video demonstration that explains the mechanics of Virtual Data Builds. Whether you're committing changes, reverting them, merging branches, or handling upstream changes, this video guide will walk you through how Virtual Data Builds simplifies these tasks without compromising the stability of your production environment.
How to use Virtual Data Builds?
Using Virtual Data Builds with Y42 doesn't introduce any additional complexity or requires extra configuration. Instead, it integrates seamlessly into your existing workflow. As a data practitioner, you continue using Git as usual. Here's how it works:
- Create branch to introduce your changes: Start by creating a branch when you need to introduce a change. The branch can be created from any branch, including main. This grants you the ability to work directly on production data without putting at risk the operational integrity of the production environment (main). If your new branch falls out of sync, merge the upstream branch into it.
- Submit PR and automatically manage stale downstream assets: Once you're satisfied with the changes, issue a pull request. If your new branch introduces changes that impact downstream dependencies, the system will not allow the changes to be merged until all flagged downstream assets by the system have been refreshed and all tests have passed.
- Trigger pipeline build on any branch: Additionally, you have the flexibility to trigger pipeline builds on any branch. This allows you to evaluate the overall state of your data warehouse based on the current set of changes.
- Merge branch: When a branch is merged, all data changes are carried over with the code changes to the target branch.
This process eliminates the need for re-builds when deploying changes. Each logical table is built once, and the physical data is reused wherever that table appears. When an asset is changed, the asset and all of its downstream dependencies become stale. Y42 automatically identifies all stale assets based on branch changes and requires the user to refresh them before any branch merges. This guarantees data integrity across your pipelines. Deployments occur at the virtual level, as all necessary physical data would already have been built by the time you decide to merge a change.
The benefits of Virtual Data Builds
The advantages of using Virtual Data Builds can be condensed into three main areas:
- Less Mental Overhead: All you need to focus on is your code. Virtual Data Builds effectively converts your code operations into assets, saving you the headache of managing environments. #EnvironmentallyFriendly
- Efficient Deployments and Rollbacks: When merging or reverting your code changes, previously materialized data assets are reused with no additional interaction required from the user beyond the standard Git process. #NoMoreRebuilds
- Reduced Data Warehouse Costs: The ability to swap views' pointers dramatically reduces storage and computation costs. Instead of rebuilding identical assets in all environments to accommodate multiple development streams, you operate with a single copy of your assets. #MinimalDWHCosts
Conclusion
The Y42 approach recognizes the inherent statefulness of data engineering. This is a fundamentally different philosophy than dbt, which is designed to operate statelessly (a given run of dbt doesn't need to "know" about any other run; it just needs to know about the code in the project and the objects in your database as they exist right now). In Y42, the state doesn’t only refer to the code changes (as in dbt’s state:modified), but also includes the state of the data warehouse. By leveraging a system of unique identifiers (UUIDs), Y42 maintains information and context from previous runs. With this philosophy, Virtual Data Builds automatically tie your code commits to the physical state of your data warehouse. This empowers you to focus on what matters most: writing code that delivers business value. Meanwhile, the Y42 system manages everything else for you: from reusing assets, to instant deployments and rollbacks, to always keeping your code, data, and schema in sync.
Virtual Data Builds are especially beneficial for teams that manage large volumes of data and aim to reduce their data warehouse costs by maximizing the reuse of their data assets – whether during development, deployment, or even when reverting changes.
In a future article, we will explore an example of Virtual Data Builds in action: how much it reduces costs under different scenarios, what the Git-DWH interaction looks like when multiple developers work in parallel, how incremental models work with Virtual Data Builds, how to create PRs, how to prevent merging stale data, how to conduct deployments with zero downtime, perform rollbacks, and much more. Until then, keep SQL’ing!
Category
In this article
Share this article
