
When we talk to fellow founders and leaders about how they utilize data, no matter which industry, the same pattern always emerges.
As the organization grows, it adds operational apps to help get jobs done. Salesforce for Sales, Pendo for Product Analytics, Google Analytics for the Website, Mailchimp for Emailing, are just some examples among many others. Each one of these apps solves a need for the organization in a specific domain. The problem is that the data is stuck and siloed within each app.
With growth comes complexity
With more apps, it becomes more challenging to manage the data that passes between them. Typically, apps provide point-to-point connections. When more and more apps are added, it becomes increasingly difficult to figure out where data comes from and how it changes. Control over the data now lies somewhere between the network of apps.
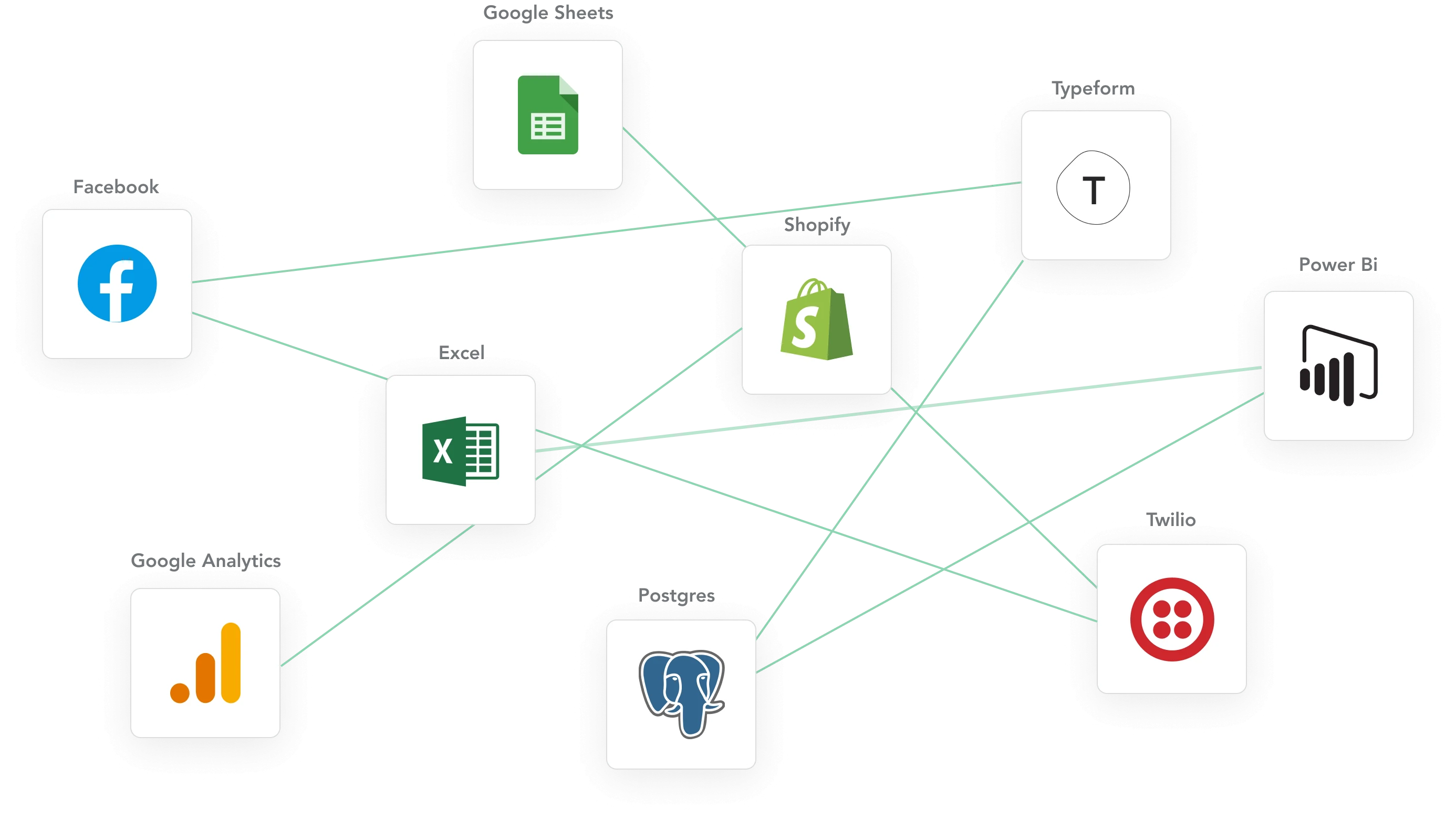
Strategic business questions are hard to answer because they require data from many, if not all, operational systems in order to capture the bigger picture. Besides, duplicated (e.g., multiple ids for the same entity) and inconsistent data will creep in. Eventually, a garbage in, garbage out situation will undermine data analysis and automation efforts , diminishing trust in data quality.
My recommendation at this point is simple: Build one centralized hub that connects and controls all individual apps and data streams (i.e., hub-and-spoke). At the heart of this operation sits a modern data warehouse. This hub operation should:
- Connect all operational apps across the organization
- Provide end-to-end visibility as to what happens with the data
- Enable ‘strategic’ data analysis, for example, by mixing customer data with product data
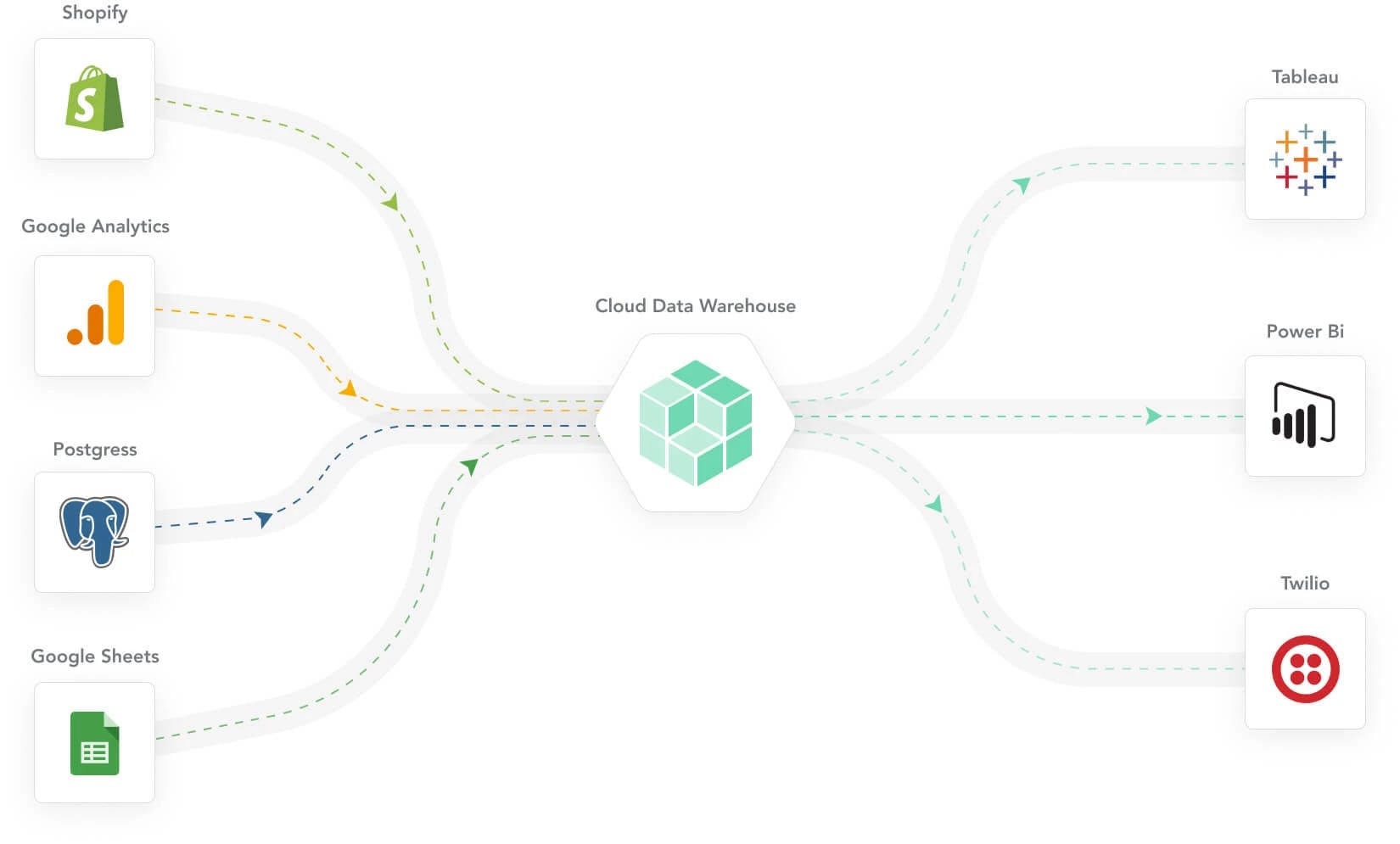
While the idea is very simple, the execution is not as straightforward. A surprising amount of infrastructure is required to keep this machine chugging.
The modern data stack — battling complexity with complexity
Typically, a data stack is often built from the top down.
- It starts with business needs. Strategic questions cannot be answered just by looking at one tool anymore, such as understanding retention, customer journeys, and key drivers for behavior.
- Dashboards and visual analysis typically come to mind first when tackling this issue. To do this, you need an independent and powerful visualization tool.
- Data integration becomes an issue. The visualization tools need to be fed with actual data from operational systems. Initially, companies use connectors to bring them together.
- Finally, raw data is not analyzable without transformation. Any strategic analysis will require a transformation layer that combines different data sources and prepares them for analysis.
In the current data tooling landscape, you need to acquire and implement one tool for each of these steps to build your organization's data platform. Everything has to be defined, configured (data engineering), and maintained (data ops).
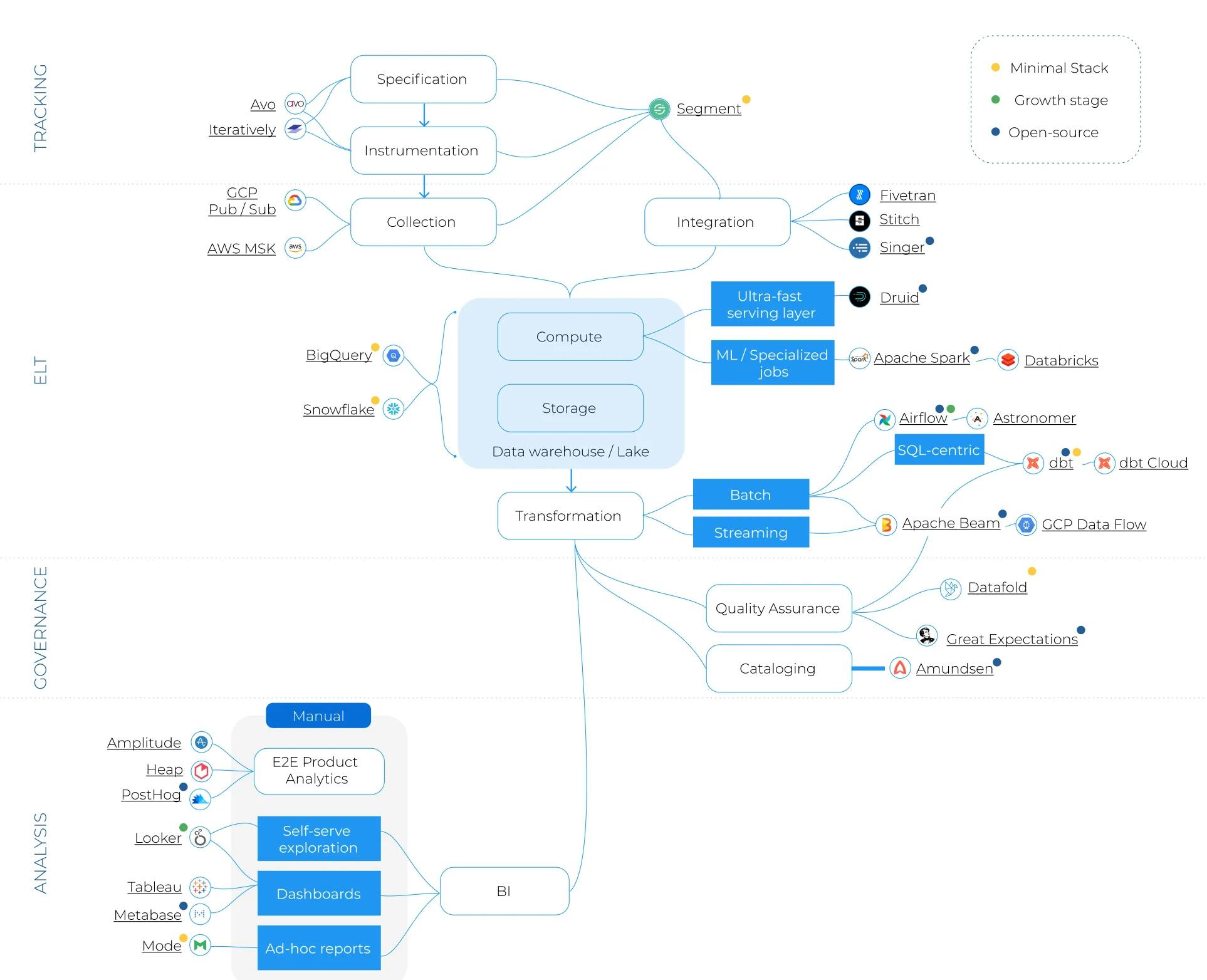
It reminds me of what’s needed when configuring a Linux server .
You have to research all the required parts and hope they work seamlessly together. While this freedom provides absolute configurability, we have heard from many that this is a daunting process, and most would prefer a solution that just works. It is also hard to anticipate future needs regarding the data stack since experience in designing a good data stack often lacks. There is a real fear of making the wrong architectural decisions, which prevents companies from even getting started.
Ultimately too much human resource is tied up in building the data platform to perform the data logistics, such as pushing data across different ecosystems, or making slight transformations so that they become compatible or analyzable.
However, even after solving the data logistics part, organizational issues remain:
- Distributed ownership of data problems leads to a slow turnaround. The people who understand the business problem and the people who understand the data platform are often separated, causing communication overhead.
- Even within the BI/Data department, roles are often split functionally between engineers, analysts, and sometimes data scientists. While this structure emphasizes specialized knowledge, there is a further split of ownership on the data platform.
- The biggest challenge ultimately is the trust chasm between data and business teams. Often, the data team builds a fortress of tooling that others don’t have access to. It is hard for business teams to understand what’s going on, and the risk of miscommunicating often-changing requirements hangs overhead.
One data platform to bind them all
We propose that the best viable solution is to merge all separate disciplines back together. Instead of managing four or more different services for extraction/loading, transformation, and visualization, manage them all from the same place. In fact, have an interface for these services that is simple enough that even business users can comprehend and build with it. This is why we’ve built Y42.
In a modern data stack like the one shown above, each tool must be ready to connect with every other tool and, therefore, be completely configurable. This is how the industry currently operates.
At Y42, we take a contrarian perspective. Similar to how Apple built all their mobile hardware to support iOS to ultimately benefit their users, we’ve built data pipelines in a vertically integrated way. This way, we can focus on building end-to-end business value instead of worrying about integrating with the next data tool.

We believe this has significant benefits for organizations and individuals:
- Fewer interfaces, less complexity, less management: Instead of maintaining four or five different data tools, we believe in one vertically integrated platform that just works.
- Single source of truth, for data and processes: Create alignment and trust by having one place to access relevant data and full visibility of the end-to-end data pipeline.
- Autonomous business users: We put these tools in the hand of business users by automating and abstracting the logistical part. We believe that any business user should be enabled to run their own analysis from adding the data to actioning it.
We believe many organizations can benefit from a unified solution.
Category
In this article
Share this article
