
With big data comes big results, but not without challenges. Sifting through huge volumes of information, checking if your integrations, models, and sources are up to date, and constantly retracing your steps can leave you thinking so much data, so little time. But what if there was another way? Drum roll, please... enter data orchestration.
Designed with the modern data analyst in mind, data orchestration simplifies your data journey. Imagine each of your data pipeline components running exactly when they should. It’s not even a problem when your integration takes longer to update, because the components that are dependent on that data will wait until the update is done before they run. Doesn’t that sound like an ideal scenario?
If you’re currently juggling multiple data workflows, stick with us. We’re here to tell you all about data pipeline orchestration, the pain points it alleviates, and how it will transform the way you use data technology.
What is data orchestration?
In a nutshell, data orchestration refers to the process of coordinating the execution of your data workflows. It allows you to automate your updates, use your data more effectively, and ultimately, streamline data-driven decision-making. Basically, data orchestration ensures the seamless integration, scheduling, and movement of your data workflows by creating dependencies between the different components of your pipeline.
Picture it like this: You have a model with an output table that showcases the daily ad spend on Tiktok, Facebook, and Google. So, the integrations that feed into this model are Tiktok Ads, Facebook Ads, and Google Ads. And because you want to know the amount of money you’re spending on ads on a daily basis, you need to update the entire pipeline every day. But it would be a pain to do that manually, wouldn’t it? So in situations like this, you orchestrate your data pipeline and schedule a daily integrations update which will then trigger an update of your model — this results in you always having the latest information in your output table.
How does a data orchestration system achieve this? Typically, it uses directed acyclic graphs (DAGs) to establish the workflows. For the non-data nerds among us, DAGs are a collection of all the tasks you’d like to run, organized by their relationships and dependencies, and customized to suit your data workflow. Using DAGs, data orchestration tools enable you to select the data points between which your data should automatically update.
How can data orchestration help you?
Now we’re getting to the good part: all the ways that data orchestration saves you time, gives you control over your data, and keeps you one step ahead of the competition. Trigger warning... let’s talk pain points!
Spot errors
There’s nothing worse than producing a report or forecast only to discover the data it’s based on is outdated or incomplete. Backtracking and chasing minor mistakes eats into time and energy that could be better channeled elsewhere — like actually deriving insights from your data and influencing business decisions. With built-in debugging tools as well as monitoring and alerts, data orchestration tools — along with platforms that offer data orchestration — immediately inform you of any issues and offer tips on how to resolve them.
Schedule updates in the right sequence
1am, 3am, 5am... you know the drill! Keeping your data pipeline moving is no mean feat — not only do you need to run workflows at certain time intervals or based on a certain logic, but you need to execute data tasks in the same order each time to maintain accuracy. Data orchestration handles this for you automatically, creating and connecting the necessary dependencies and updating the data between the different elements of your pipeline. Gone are the days spent setting 10 separate schedules! With data orchestration, you only need to set a single schedule.
Strengthen your data management
With fragmented data sources, models, and automations, it’s difficult to create and maintain your data workflows, as well as trace a calculation back to the data they used. And if you can’t easily spot and fix errors, or monitor how your data is being processed, how can your business use its data effectively? A robust data orchestration system gives you full oversight of your pipeline and its processes, ultimately strengthening your data management so you can unleash its true value.
Orchestrate your data pipeline with Y42
You now know how data orchestration works and why it’s beneficial for you to start orchestrating your data pipelines. But in order to get there, you need to find a data analytics tool that will allow you to complete this function.
Have you heard about Y42? This full-stack data platform offers you the flexibility to set up your entire data pipeline, all in one place. First, you integrate your data, then you model it, and then you set up any data exports you might need. Once all of these steps are complete, the data orchestration engine is ready to come in. It can actually be set up in just a few clicks:
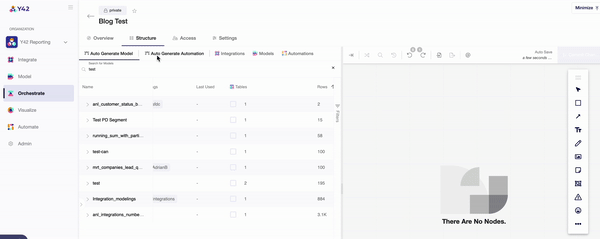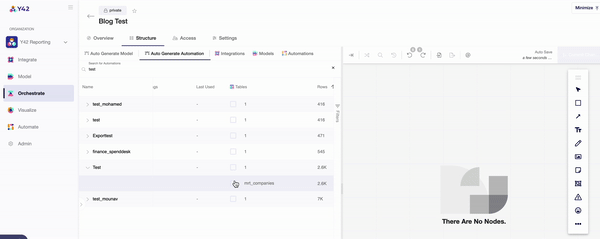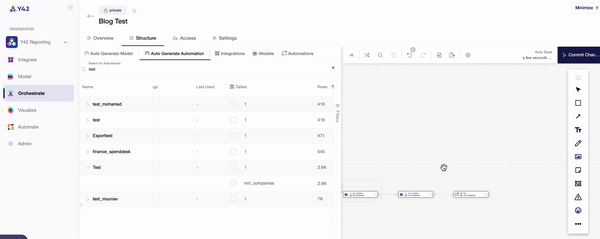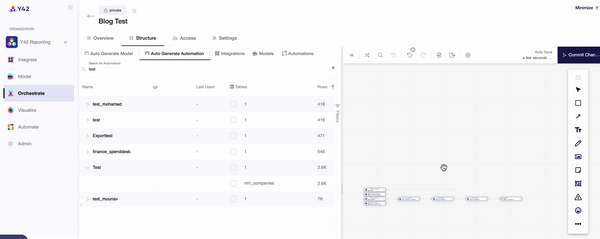
- Once you are in the orchestration layer, you will be prompted to create a DAG made up of the data components you wish to analyze.
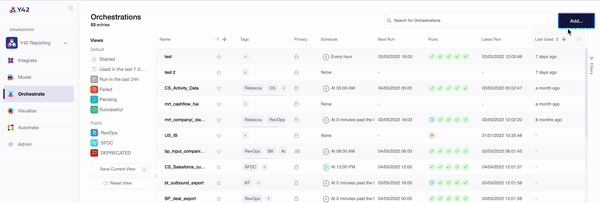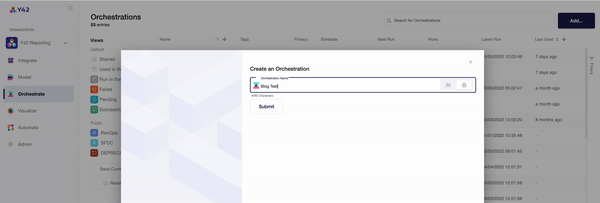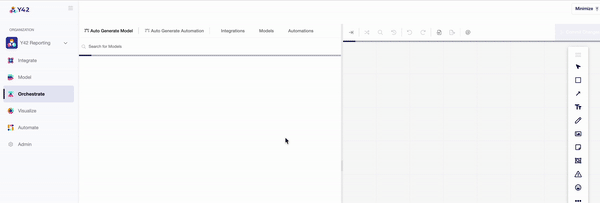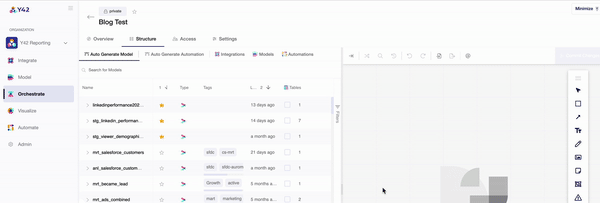
- The ‘Structure’ tab then allows you to pull in your desired components individually, or you can use the auto-generate function to automatically connect your data sources and models.
- Once you’ve committed your orchestration, you’ll be able to schedule its run time. This can be as frequently as every 30 minutes, every hour, every day, or even weekly — whenever you want.
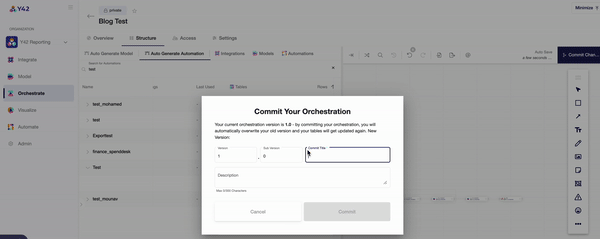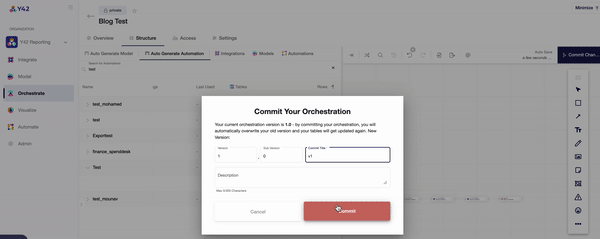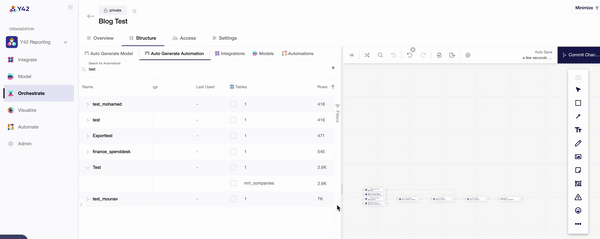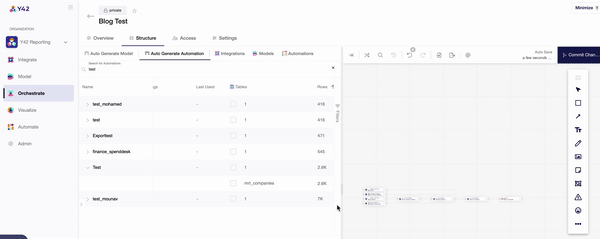
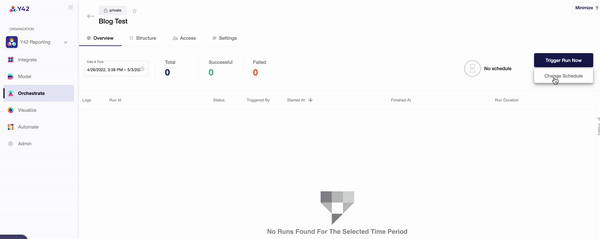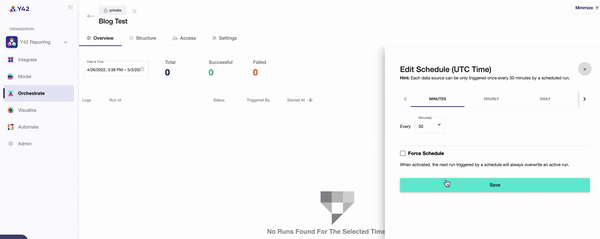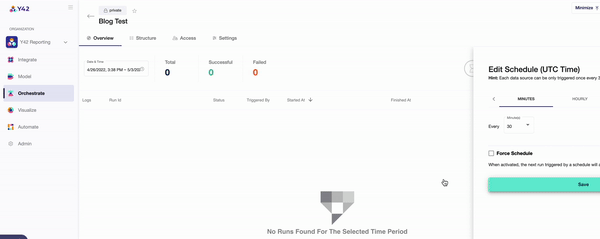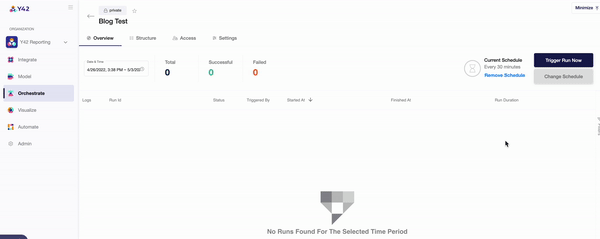
- You can keep track of your data orchestrations in the ‘Overview’ tab, which indicates when each DAG ran and for how long. For a more in-depth overview, Y42’s data lineage layer shows every aspect of your data pipeline all at once, so that you can trace every single step.
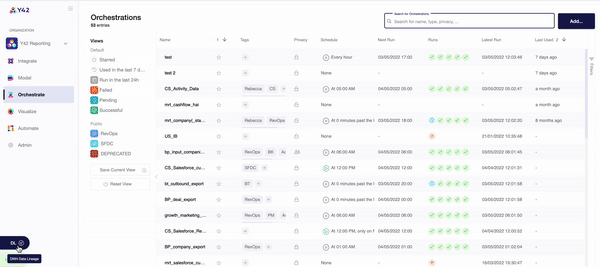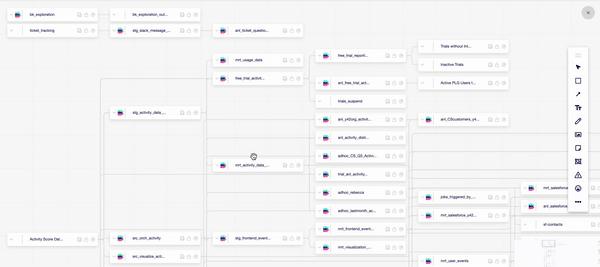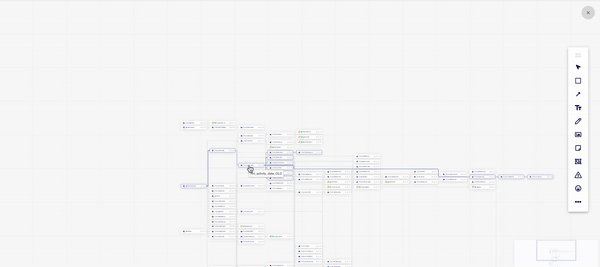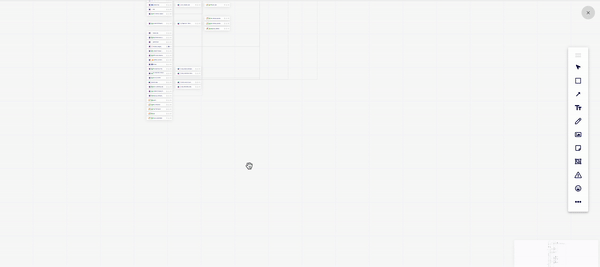
This automated nature of Y42’s orchestration layer is designed to ensure your data is as accurate as possible. Each stage of the data orchestration process must be completed for the tool to move on to the next one. Should the system run into an error along the way, you’ll be notified immediately — aiding data management by giving you the chance to tackle any issues before they have an impact.
No more frantically switching between programs to revise and refresh all your data! Once each of your dependencies is ready to go, your orchestration can move forward. All you need to do is decide which output table to use and when you want that data. It’s really that simple.
Got any questions? Want to know how orchestrating your data could benefit your specific use case? Then get in touch with the team. Our data experts would be more than happy to clarify any of your doubts.
Category
In this article
Share this article
