
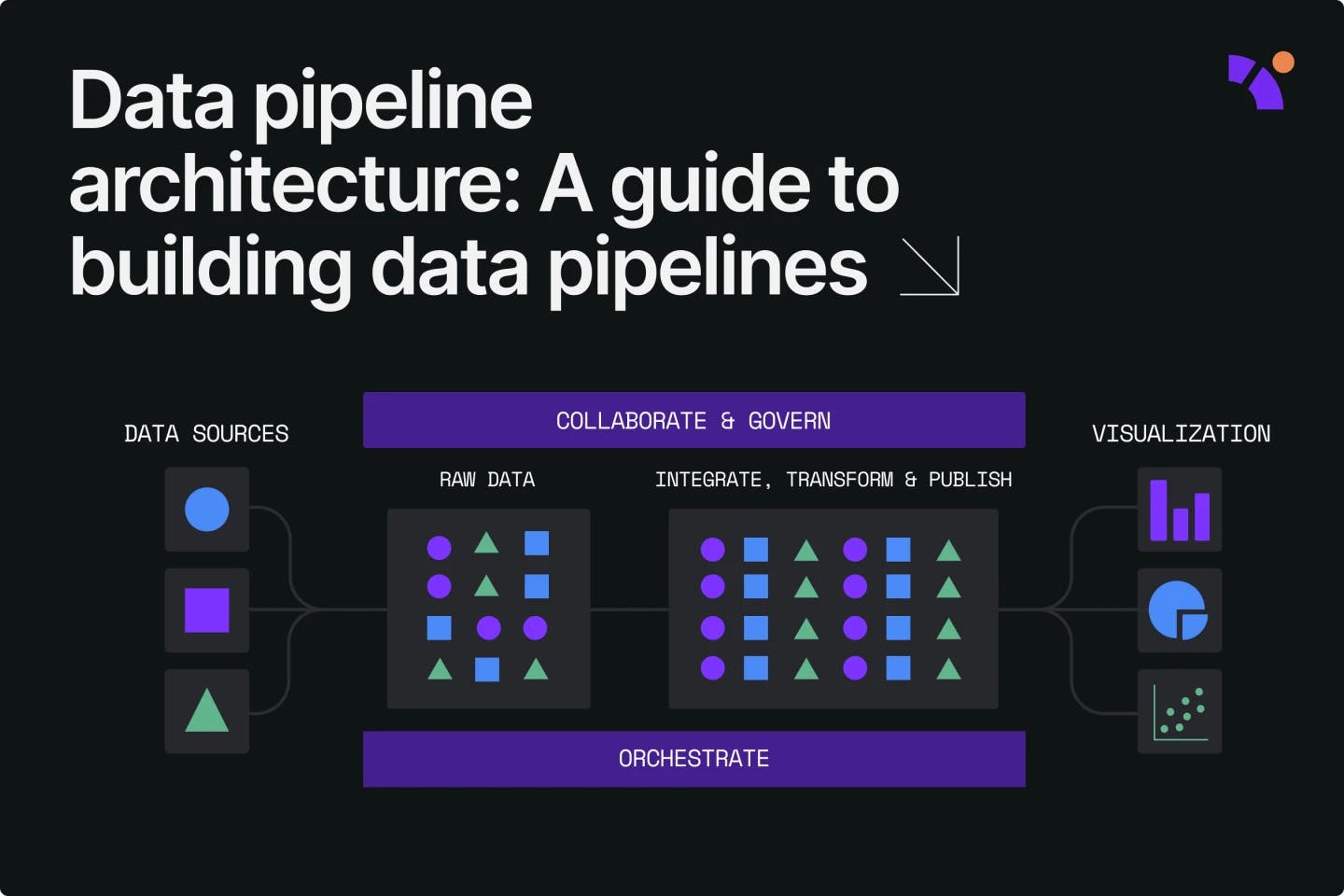
What is a data pipeline architecture?
A data pipeline moves data from its source to its destination. The data pipeline architecture is the collection of tools, code, and systems that support the movement of this data.
In the physical world, a bridge’s metal frame, beams, and foundation allow cars and people to move across a river or lake. Likewise, the data pipeline architecture provides the support systems that allow various types of data to move through the data pipeline, where it can be transformed into a more useful format for analytics and further processing.
Why is a good pipeline architecture design important?
A good data pipeline architecture streamlines the data ingestion, transformation, and orchestration process by reducing complexity.
A well-designed data pipeline architecture ensures that all your data is ingested correctly and in real time. As a result, you can guarantee data infrastructure uptime, which your organization’s key data stakeholders rely on.
A poorly designed data pipeline architecture can wreak havoc on your data and the valuable insights buried within. Just as you wouldn’t want a leaky water pipe in your home, you don’t want a leaky data pipeline. A good data pipeline architecture serves as the single source of truth for your entire organization. This ensures compliance with both internal data security standards and external regulations, such as the General Data Protection Regulation (GDPR).
A well-designed pipeline architecture also fosters healthy collaboration among the data engineers in your team. This collaboration also extends to the analytics engineers and data analysts who are external to your core data engineering team. Synergies within and outside the data engineering team increase productivity and overall team performance.
Common features of a data pipeline architecture design
A good design for your data pipeline architecture should align with the goals of your business. There are certain features that will be a bigger priority for you than others.
ETL pipeline with data warehouse
Organizations with a single data warehouse that stores all their useful data can use an ETL pipeline to move data into the warehouse. ETL stands for extract, transform, load. On the backend, this strategy is resource-intensive.
Entire data engineering teams need to make new data inputs compatible with the data warehouse. These teams have to combine and clean data from multiple sources and formats before this data can be sent there. They also need to provide active support to prevent disruptions to the availability of this data. On the frontend, data analyst teams have to query this data to support the business teams that use it to extract insights.
This architecture design promotes data integrity, since all teams are working off the same set of data. However, data warehouses are designed to handle structured data in a batchwise fashion, limiting your ability to make data readily available to downstream users. In addition, the dependence on large, highly specialized teams to transform the data creates data processing bottlenecks.
Data pipeline plus data lake
A data lake allows you to store a wide variety of data in its original format (both structured and unstructured). However, since this data cannot be readily queried as it can in a data warehouse, you end up needing specialized resources to extract the data from the lake, transform it, and deploy it for use in analytics platforms.
While the data lake broadens the types and volumes of data you can store, it takes more effort to prepare the data for analytics teams to use. Once again, specialized data engineering teams become a bottleneck to rapid data processing.
Modern data stack pipeline
The modern data stack has become increasingly common. A combination of ingestion tools, such as Airbyte; data transformation tools, such as dbt; cloud data warehouses, such as Snowflake and BigQuery; and visualization tools are widely available.
However, this is not a cohesive process, as it quickly leads to data silos. These tools rarely communicate with each other, crippling knowledge-sharing between departments. Although these individual tools are very agile, they don’t necessarily translate into increased agility for your business as a whole, as data engineering teams must now be brought in to stitch together the outputs and underlying infrastructure.
ELT pipeline with data warehouse
ELT stands for extract, load, transform. With an ELT pipeline, data is extracted from a source and loaded into a cloud data warehouse where the data is then transformed. Since no secondary server is required, this process is faster than ETL.
The high costs and limitations associated with storage capacity have been overcome with the rise of cloud-based storage systems. This has made ELT data pipelines more attractive than the more traditional ETL pipelines.
Mistakes to avoid when designing data pipelines
Working backward is best practice when designing a data pipeline as it can help you avoid the following common mistakes.
Not being clear about the data pipeline’s final output
Your data analysts or business analytics team are the primary users of the data from a data pipeline. They are the ones who are most capable of understanding the insights the data has to offer, meaning you need to ensure that the output from your data pipeline meets their needs. Will the data pipeline output be used for data visualization? To drive analytics? To develop new data apps? These are some of the questions that should be asked and answered up front when designing a good data pipeline.
Not knowing the types of data that are important to your business
Data can be put into two broad categories: structured and unstructured. Ingesting and processing these two types of data requires very different tools. You don’t want to select a data warehouse as your data storage only to find out later that most of your data is unstructured, like videos or sensor information. You should clarify which types of data are important to your business up front, so that you can design a data pipeline that works well.
Not being cloud-ready
For legacy businesses, adopting the cloud is critical for designing your data pipeline. The cloud gives you the flexibility and scalability you need to process large datasets in real time through your data pipeline. Migrating to the cloud is no easy feat. You can always design a legacy data pipeline on-prem, of course — but your business may be left behind as you realize your IT infrastructure is unable to handle the sheer volume and variety of data it needs to grow and stay relevant.
How to design and build a data pipeline
Let’s work through a simple way to build a data pipeline using an ELT strategy.
- Locate your data source and ensure you have the appropriate level of access.
- Integrate your data sources with your cloud data warehouse of choice (either Snowflake or BigQuery).
- Build your data models to transform the raw source data from your data warehouse.
- Control access to your data models by assigning viewers and collaborators. Make data ownership and accountability a priority by assigning owners to the data models and experts to single out the stakeholder with the most business context.
- Set up your orchestrations to automate the triggering process by following your logic sequence and schedule. Once your orchestration is set up, it will run automatically without further interaction from you.
- Create and deploy data tests to flush out breakdowns in your data workflow. This prevents failures.
- Set up notifications to alert designated users of the data’s progress through the data pipeline and any issues.
- Once your data pipeline is production-ready, you can share your data tables with downstream applications and/or data users by using reverse ETL. These end users can now build visualizations based on a single source of truth — your data pipeline.
Design efficient data pipelines with Y42
There are many features to keep in mind when designing and building your data pipeline architecture. Each component is critical to the success of your data pipeline. An efficient data pipeline enables you to offer centralized access to your company’s data. Improved access increases data literacy among non-technical users, empowering them to self-serve. This frees you up to implement DataOps best practices, as you no longer have to respond to frequent data requests from multiple departments.
Platforms like Y42 give you access to all these different components within one interface, making it accessible to all types of data professionals. Y42 allows you to ingest, transform, orchestrate, publish, monitor, and visualize data within a platform that sits on top of your cloud data warehouse.
The only thing worse than not having a modern data pipeline in place is having an outdated one — or worse still, a leaky pipeline that no one can rely on. If you want to stay on top of your data in a single platform with the power of best-of-breed data pipeline features, we invite you to book a call with our data experts to find out more about our innovative Modern DataOps Cloud.
Category
In this article
Share this article
