
Data governance is the practice of ensuring that data is appropriately managed, protected, and used in an organization. It involves establishing policies, procedures, and systems to manage data assets and ensure that they are used in a way that aligns with the organization’s goals and objectives.
In the context of data pipelines, data governance is especially vital because it helps ensure that the data used to design, operate, and maintain pipelines is accurate, reliable, and secure.
What is a data governance stack?
A data governance stack refers to the set of tools, techniques, and technologies used to support an organization’s data governance efforts. All the components and practices involved in a data governance stack are particularly important for ensuring that data pipelines are safe, reliable, and efficient.
In this article, we will dig deeper into the key components of a data governance stack and explore how organizations can effectively implement and maintain a data governance framework.
Benefits of a data governance stack
A data governance stack can bring numerous benefits to data professionals, including:
Improved data accuracy and quality
By implementing data quality checks and processes, a data governance stack ensures the availability of accurate, complete, and up-to-date data. It can help reduce the risk of errors and improve the pipeline’s reliability.
Enhanced data security
Data teams often deal with sensitive data, such as information about the location and condition of the pipelines. By implementing strong security measures, such as encryption and access controls, a data governance stack can help protect pipeline data from unauthorized access or misuse, reducing the risk of data breaches and other security threats.
Increased efficiency
A well-designed data governance stack can help data professionals manage and use data more efficiently and effectively to support their operations and decision-making. It supports enhanced data access so that data professionals can promptly find and use data for their operations. By ensuring that data used in pipeline operations meets specific standards in terms of accuracy, completeness, and consistency, a data governance stack can reduce the time and effort required to work with poor-quality data.
Enhanced compliance with regulations
Pipeline data is subject to several laws and regulations governing its collection, storage, and usage. A data governance stack can help data professionals comply with these regulations, avoiding costly fines and legal liabilities. It can help organizations meet regulatory requirements and industry standards, helping to reduce the risk of non-compliance and potential penalties.
Better decision-making
Accurate and reliable data is crucial for making informed decisions. A data governance stack helps ensure that the data used by data experts is of high quality, which enables business stakeholders to make better-informed decisions in turn.
Enhanced stakeholder trust
Data governance tools help build a trustful collaboration between data teams and other organizational stakeholders by demonstrating responsible and ethical management and protection of data assets.
To summarize, a data governance stack can help data professionals better manage and protect their data assets, improve data quality and accuracy, and ensure responsible data usage.
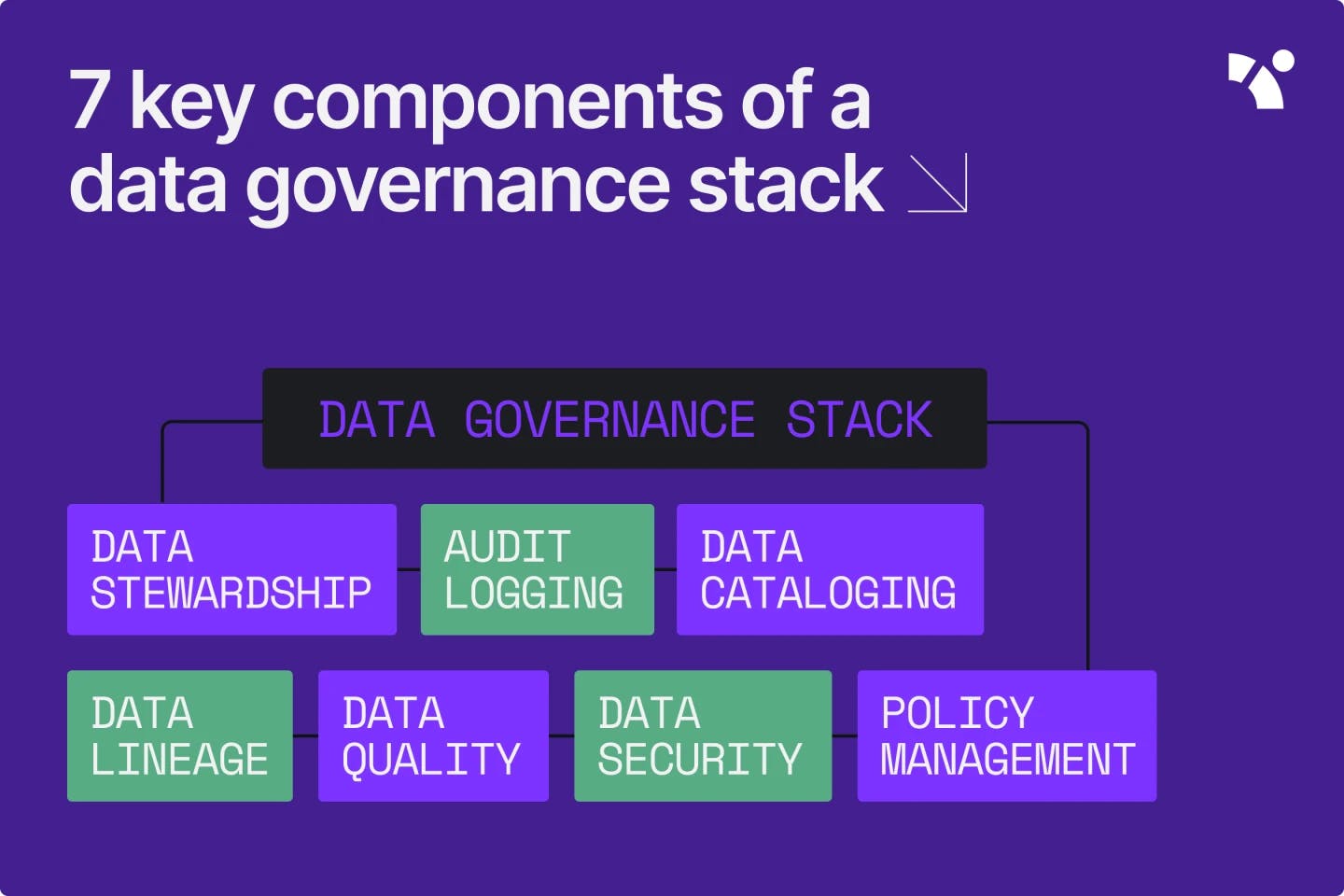
7 key components of a data governance stack
Here are seven key components of a data governance stack:
Data stewardship
Data stewardship refers to managing and protecting data within an organization. Organizations need data stewardship to oversee the quality, security, and accessibility of their data and ensure that it is used in a way that is consistent with their data governance policies.
To use data stewardship effectively, organizations should establish clear roles and responsibilities for data management and define and enforce data governance policies and procedures.
Good data stewardship is a prerequisite for effective data governance, helping organizations manage and protect their data and ensure its integrity, availability, and confidentiality.
Audit logging
Audit logging is the process of recording and tracking changes made to data within an organization. Organizations need audit logging to track and investigate any issues with their data and identify trends and patterns in it.
The process involves capturing a record of all data-related activities, such as data creation, modification, and deletion, as well as the users and systems involved in these activities. To use audit logging effectively, organizations should set up processes for implementing and maintaining audit logs and define the types of data-related activities that should be logged.
Data cataloging
Data cataloging is the method of organizing and creating an inventory of all the data within an organization, typically in a central repository or data catalog. By providing a centralized data repository, you can make your data easier for authorized users to discover and access.
The implementation of data catalogs involves creating a comprehensive inventory of the organization’s data assets, including descriptions, metadata, and other relevant information about each data set.
Data cataloging benefits your data governance stack by improving your data discoverability, which allows you and your teams to locate data more efficiently, and by facilitating data sharing and collaboration within your organization.
Data lineage
Data lineage refers to the history and context of data. It includes where the data came from, how it has been transformed, what it has been used for, and where it is stored. Understanding data lineage can help data professionals trace the provenance of data and ensure its accuracy and reliability.
A comprehensive historical data record, such as a data lineage, ensures enhanced compliance, data quality, and collaboration.
Data quality
Data quality refers to the accuracy, completeness, and relevance of data. Ensuring data quality is critical to the reliability and integrity of the data governance stack. Several key components can help improve data quality in a data governance stack, including alerts and tests.
Alerts are used to notify users when data quality issues are detected. These can be configured to trigger based on specific conditions, such as when data falls outside of expected ranges or is missing or incomplete. Alerts can be sent via email, text message, or other channels and can help ensure that data quality issues are addressed promptly.
Tests are used to validate the quality of data. These include data integrity checks, which assess data to meet specific rules or constraints; tests at the table level, such as testing the number of columns and the freshness of the data; and tests at the column level, such as checking for null values, accepted values, or data types. Tests can be run manually or automatically and help identify and correct data quality issues before they become a problem.
Together, these components help to ensure that data teams have access to high-quality data.
Data security
Data security refers to the measures and controls used to secure data against unauthorized access, modification, or disclosure.
- This is an essential aspect of data governance, as it helps to ensure data confidentiality, integrity, and availability, protect critical data, and significantly reduce the risk of data breaches and other security threats. There are several methods to secure data in a data governance stack, including access controls, privacy controls, and database firewalls.
- Access controls manage and restrict data access, ensuring sensitive data access to authorized users only. They include user authentication, access permissions, and data encryption measures.
- Privacy controls are used to protect the privacy of individuals whose data is being collected and stored. These controls include processes such as data masking, de-identification, and data anonymization.
- A database firewall is a security system that tracks and controls incoming and outgoing traffic to and from a database. It is designed to protect the database from external attacks and unauthorized access, and can be configured to allow or block specific types of traffic based on rules and policies.
Together, these components can help ensure that data pipelines are secure and protected from any security incidents.
Policy management
Policy management is the process of defining, implementing, and enforcing data governance policies within an organization. It includes establishing guidelines for data use, storage, and disposal.
Within a data governance stack, policy management typically involves developing and implementing in-house process definitions that outline the specific actions and procedures that must be followed to ensure compliance with relevant laws, regulations, and industry standards.
Overall, effective policy management in a data governance stack is essential for ensuring that data is handled responsibly and correctly, and also for building trust with customers, stakeholders, and regulators.
Y42 as your single data governance tool
A data governance stack does not have to be as complicated as it sounds. Choosing the right data governance tool can make all the difference for your organization.
Fortunately, the Y42 Modern DataOps Cloud automates and simplifies the implementation of crucial elements of data governance so that you can reduce human errors in your data governance practices. Some of Y42’s key data governance features include:
- Auto-generated data catalog
- Annotated data lineage
- Data contracts
- Multichannel alerts
- Data steward accountability
- Lineage-aware access control
- Manual and automated data tests
With Y42, all your data governance needs are served through a single interface.
Category
In this article
Share this article
